Lattice Land
Hello! You just arrived in lattice land! Lattice land is a collection of C++ libraries compatible with NVIDIA CUDA framework. Most of the libraries implement abstract domains for constraint reasoning a new kind of data structure based on abstract interpretation, lattice theory and constraint reasoning. This is a book presenting our research project, the involved research papers and the code documentation.
This project is available on github.
API Documentation
- cuda-battery: Memory allocators, vector, utilities and more which run on both CPU and GPU (CUDA). See also the chapter CUDA-Battery Library.
- lala-core: Core definitions of the formula AST and abstract domain.
- lala-parsing: Utilities to parse combinatorial formats including flatzinc (.fzn) and XCSP3 (.xml).
- lala-pc: Propagator completion abstract domain representing a collection of refinement functions. It implements propagators, an essential component of constraint solver.
- lala-power: Abstract domains representing disjunctive collections of information. It includes the search tree and branch-and-bound.
- turbo: Abstract constraint solver building on all other libraries.
- lattice-land.github.io: The repository hosting this book and the libraries documentation.
Introduction
The main objective of the CUDA battery library is to make it easier to develop software fully executing on the GPU. This is in contrast to applications where the CPU is the “director”, and the GPU is only there to execute small kernels performing specific parallel tasks. We want to have the whole computation on the GPU when possible. Why you asked? Because it is more efficient as we avoid round-trips between CPU and GPU; although calling a kernel is very fast, the memory transfers are still costly. In the research project lattice-land, we also explore pure GPU computation as a new paradigm where many small functions collaborate in parallel to reach a common goal.
Developing systems in CUDA is a daunting task because the CUDA API is reminiscent of C programming, and it lacks modern C++ idioms and data structures. For instance, memory allocations and deallocations are managed by malloc/free variants, arrays are pointers and we do not have access to the C++ STL. Moreover, due to the specificities of the CUDA API, it is usually difficult to program a single function working on both the CPU and the GPU. Although it is rarely possible to have the exact same algorithm on both CPU and GPU, there are often algorithmic components that are shared. Having them both on CPU and GPU can help to verify the parallel version produces the same result as the sequential version, and it also allows us to benchmark CPU vs GPU.
The cuda-battery library reimplements basic data structures from the STL in a way such that the same code runs on both CPU and GPU.
One of the only technical differences between CPU and GPU is memory allocation.
To overcome this difference, we provide various allocators that allocate memory in the CPU memory, unified memory, and GPU global and shared memory.
The idea is then to parametrize your classes (through a C++ template) with an allocator type and, depending on whether you run your algorithm on the CPU or GPU, to instantiate it with a suited allocator type.
Among the supported data structures, we have vector, string, variant, tuple, unique_ptr, shared_ptr, a variant of bitset and many utility functions.
In addition to the STL, we provide an abstraction of the memory accesses to enable non-atomic (sequential) and atomic (parallel) read and write operations.
The memory abstraction is necessary when writing code working on both GPU and CPU, but also when writing GPU parallel code that can work in global and shared memory, and at the thread, block, grid and multi-grid level.
This library aims to be generic and usable in different kind of projects, but when a design decision needs to be made, it will be influenced by the needs of the project lattice-land.
Everything is under the namespace battery::.
The Doxygen documentation is available here.
Due to lack of time, these are often partial implementation of their STL counterpart, and there are sometimes (documented) differences.
NVIDIA is developing libcudacxx, a version of the standard C++ library compatible with GPU, and with extensions specific to CUDA.
cuda-battery can be seen as an extension of libcudacxx, and we intend to remove the data structures proposed here as soon as they become available in libcudacxx.
Another well-known library is thrust, but it does not share the same goal since it hides the parallel computation inside the data structure, e.g. reduce on a vector is automatically parallelized on the GPU.
Note that this tutorial does not introduce basic CUDA concepts: it is for (possibly beginners) CUDA programmers who want to simplify their code. For an introduction to CUDA, you can first refer to this tutorial. Finally, the full code of all examples given here is available in a demo project.
Transferring data from the CPU to the GPU
One of the first tasks a CUDA programmer is facing is to transfer data from the CPU to the GPU.
Using this library, it is very straightforward, and it is always the same scheme.
To illustrate the concepts of this library, we implement a map(v, f) function which applies a function f to all elements of the sequence v in-place.
We firstly need to transfer the data v to the GPU using managed memory, and it is as simple as that:
int main() {
std::vector<int> v(1000, 50);
battery::vector<int, battery::managed_allocator> gpu_v(v);
return 0;
}
Now we must pass gpu_v to a CUDA kernel.
However, there is a slight technical issue due to the weird parameters passing semantics of CUDA kernel (__global__ function): we must pass primitive types or pointers to the functions.
Indeed, trying to pass an object by reference or copy is undefined behavior.
This is only a restriction on __global__ functions, and once inside the kernel, passing by reference or copy works well (when calling __device__ functions).
You could simply pass the data as kernel<<<1,1>>>(gpu_v.data(), gpu_v.size()), but you lose all the advantages of vector when programming in the kernel.
The solution is to wrap gpu_v inside a pointer, which we can still do the C++ way using unique_ptr:
using mvector = battery::vector<int, battery::managed_allocator>;
__global__ void map_kernel(mvector* v_ptr) {
mvector& v = *v_ptr;
// ... Compute on `v` in parallel.
}
void map(std::vector<int>& v) {
auto gpu_v = battery::make_unique<mvector, battery::managed_allocator>(v);
map_kernel<<<256, 256>>>(gpu_v.get());
CUDAEX(cudaDeviceSynchronize());
// Transfering the new data to the initial vector.
for(int i = 0; i < v.size(); ++i) {
v[i] = (*gpu_v)[i];
}
}
Due to the C++ RAII idiom, the managed memory of both the GPU unique_ptr and mvector is automatically freed when leaving the scope of the function.
Importantly, the memory allocated on the CPU must be freed by the CPU, even if it is accessible by the GPU, and vice-versa.
But you should not encounter this issue if you use this idiom to pass data from the CPU to the GPU.
CMake CUDA Project
In order to compile and test the code presented above, you will need to add the headers of this library to nvcc.
nvcc -I cuda-battery/include demo.cu
We prefer to delegate the management of dependencies to CMake, a build automation tool.
However, creating a CMake project for hybrid CPU/GPU code is not an easy task, and we provide a demonstration CMake project in cuda-battery/demo.
You can start your own project by copying the demo folder and modifying the name of the project inside the file CMakeLists.txt.
To compile and run this project, you can write:
cd cuda-battery/demo
mkdir -p build/gpu-debug
cmake -DCMAKE_BUILD_TYPE=Debug -Bbuild/gpu-debug
cmake --build build/gpu-debug
./build/gpu-debug/demo
It compiles the demo project in debug mode using the GPU compiler (nvcc), along with the unit tests (using the Google testing framework GTest).
You can also compile it in release mode by simply changing debug to release in the previous commands.
To run the tests, the command ctest can be used as follows:
ctest --test-dir build/gpu-debug/
Among the characteristics of this project:
- Files have the
.cppextension instead of the.cuextension. - It compiles code for the native GPU architecture by default (so for the GPU of the computer you are compiling your code on).
This can easily be changed if you are cross-compiling by defining the flag
CMAKE_CUDA_ARCHITECTURESat the configuration stage:
cmake -DCMAKE_CUDA_ARCHITECTURES=70 -DCMAKE_BUILD_TYPE=Release -Bbuild/gpu-release
- Several useful options inherited from cuda-battery (enabling C++20 and constexpr extension).
- A testing framework where you can write your CPU tests using Google Test framework (see
demo/tests/demo_test.cpp) and your hand-made GPU tests (seedemo/tests/demo_test_gpu.cpp). - Moreover, when testing GPU code, we verify there is no memory leaks or some data races (using
compute-sanitizer).
We have documented the CMakeLists.txt so you can adjust it to your own project.
In-Kernel Memory Allocation
The typical way to allocate data structures shared by all threads or blocks in a CUDA kernel is to get all the memory allocations done before the kernel starts. However, when developing a larger CUDA kernel, it is frequent to rely on intermediate structures that are only temporary and are deleted before the end of the kernel. It might be difficult, or at best inconvenient, to allocate everything before the start of the kernel. Moreover, to follow good software engineering practice, these temporary structures should be hidden from the user of the kernel.
Thread-local Memory
Thread-local memory is a chunk of memory that is only accessed by a single thread. This is the default allocation mode when declaring a variable in CUDA kernel, hence it does not need any support from this library.
Block-local Memory
Block-local memory is a chunk of memory that is only accessed by the threads of a single block. To avoid any ambiguity: “block-local memory” is conceptual and might reside in global memory; it is not necessarily in shared memory.
A simple use-case is when blocks need to work on different copies of an original array.
Suppose *v_ptr is an array shared by all blocks.
In the following kernel, we show how to use battery::make_unique_block to copy *v_ptr into a block-local vector v_block.
using gvector = battery::vector<int, battery::global_allocator>;
__global__ void block_vector_copy(mvector* v_ptr) {
battery::unique_ptr<gvector, battery::global_allocator> v_block_ptr;
gvector& v_block = battery::make_unique_block(v_block_ptr, *v_ptr);
// Now each block has its own local copy of the vector `*v_ptr`.
// ...
// We must synchronize the threads at the end, in case the thread holding the pointer in `unique_ptr` terminates before the other.
cooperative_groups::this_thread_block().sync(); // Alternatively, `__syncthreads();`
}
Without this facility, we would need to initialize n copies of the vector in the host code and pass them as parameters to the kernel.
Finally, the function make_unique_block synchronizes all threads of the current block before returning, therefore v_block is directly usable by all threads.
Before you use this technique, keep reading because you might need to increase the size of the heap and stack.
Avoiding Obscure CUDA Runtime Errors
Developing an entire system within a single kernel can easily lead to CUDA runtime error due to overflow of the allowed heap and stack memory. The heap memory is by-default limited to 8 MB for allocations taking place in the kernel. If you allocate more than 8 MB, which is not very difficult, you will run into an error of the style “CUDA runtime error an illegal memory access was encountered”. In that case, you must increase the size of the heap, and this can be done as follows:
// Multiply by 10 the default value, so now we have 80MB.
void increase_heap_size() {
size_t max_heap_size;
cudaDeviceGetLimit(&max_heap_size, cudaLimitMallocHeapSize);
CUDAE(cudaDeviceSetLimit(cudaLimitMallocHeapSize, max_heap_size*10));
cudaDeviceGetLimit(&max_heap_size, cudaLimitMallocHeapSize);
printf("%%GPU_max_heap_size=%zu (%zuMB)\n", max_heap_size, max_heap_size/1000/1000);
}
int main() {
increase_heap_size();
auto vptr = battery::make_unique<mvector, battery::managed_allocator>(100000, 42);
auto ptr = vptr.get();
block_vector_copy<<<256, 256>>>(ptr);
CUDAEX(cudaDeviceSynchronize());
}
For the stack, which is allocated per-thread, the problem can quickly arrive if you have many function calls and local variables. In that case you can increase the size of the stack as follows:
void increase_stack_size() {
size_t max_stack_size = 1024;
CUDAE(cudaDeviceSetLimit(cudaLimitStackSize, max_stack_size*10));
cudaDeviceGetLimit(&max_stack_size, cudaLimitStackSize);
printf("%%GPU_max_stack_size=%zu (%zuKB)\n", max_stack_size, max_stack_size/1000);
}
For information, the stack frames are stored in global memory, but the compiler will try its best to place them in the registers and caches when possible.
Grid-local Memory
Similarly to the previous section, we sometimes wish to initialize, inside the kernel, data that is shared by all blocks.
Once again, we suppose to have an original array *v_ptr that we wish to copy, but per-grid and not per-block.
__global__ void grid_vector_copy(mvector* v_ptr) {
battery::unique_ptr<gvector, battery::global_allocator> v_copy_ptr;
gvector& v_copy = battery::make_unique_grid(v_copy_ptr, *v_ptr);
// `v_copy` is now accessible by all blocks.
// ...
// Same as with block-local memory, we want to guard against destructing the pointer too early.
cooperative_groups::this_grid().sync();
}
To synchronize among threads, both make_unique_block and make_unique_grid rely on cooperative groups.
In the case of make_unique_grid, CUDA requires the kernel to be launched with a different syntax:
int main() {
increase_heap_size();
auto vptr = battery::make_unique<mvector, battery::managed_allocator>(100000, 42);
auto ptr = vptr.get();
void *kernelArgs[] = { &ptr }; // be careful, we need to take the address of the parameter we wish to pass.
dim3 dimBlock(256, 1, 1);
dim3 dimGrid(256, 1, 1);
cudaLaunchCooperativeKernel((void*)grid_vector_copy, dimGrid, dimBlock, kernelArgs);
CUDAE(cudaDeviceSynchronize());
return 0;
}
I am not sure why the syntax is different, but since it is a fairly recent feature, it might be improved in future releases.
Multi-grid Memory
For now, we do not support multi-grid memory allocation.
Shared Memory Allocator
We show how to use shared memory using a memory pool allocator.
using pvector = battery::vector<int, battery::pool_allocator>;
__global__ void map_kernel_shared(mvector* v_ptr, size_t shared_mem_capacity) {
// I. Create a pool of shared memory.
extern __shared__ unsigned char shared_mem[];
battery::unique_ptr<battery::pool_allocator, battery::global_allocator> pool_ptr;
// /!\ We must take a reference to the pool_allocator to avoid copying it, because its copy-constructor is not thread-safe! (It can only be used by one thread at a time).
battery::pool_allocator& shared_mem_pool = battery::make_unique_block(pool_ptr, static_cast<unsigned char*>(shared_mem), shared_mem_capacity);
// II. Transfer from global memory to shared memory.
battery::unique_ptr<pvector, battery::global_allocator> shared_vector;
size_t chunk_size = chunk_size_per_block(*v_ptr, gridDim.x);
auto span = make_safe_span(*v_ptr, chunk_size * blockIdx.x, chunk_size);
pvector& v = battery::make_unique_block(shared_vector, span.data(), span.size(), shared_mem_pool);
// III. Run the algorithm on the shared memory.
block_par_map(v, [](int x){ return x * 2; }, blockDim.x, threadIdx.x);
__syncthreads();
// IV. Transfer back from shared memory to global memory.
for(int i = threadIdx.x; i < v.size(); i += blockDim.x) {
(*v_ptr)[chunk_size * blockIdx.x + i] = v[i];
}
}
We initialize one pool allocator per-block using the same technique as shown before.
However, we must be careful to take the pool_allocator by reference because its copy-constructor is not thread-safe; similarly to shared_ptr it maintains a shared counter to its memory pool.
Since memory allocation is done by only one thread anyway, it does not make sense to have multiple copies of this allocator.
The next step is to transfer the vector to the shared memory.
Each block works on a chunk of the initial array.
Therefore, we do not want to move the whole array in shared memory, but only the part of interest for that block.
To achieve that, we compute the size of the chunk using chunk_size_per_block and create a view of the vector covering only that chunks.
We use std::span to model the view.
Note that we can use the STL std::span because all its methods are constexpr, and we have the NVCC flag --expt-relaxed-constexpr inherited from cuda-battery.
We then copy this span into the vector v which is in shared memory.
The algorithm block_par_map is then called on v for each block.
The last step is to transfer the memory from the shared memory to the global memory.
After each block finished computing, the map function has been applied to each element of the initial vector.
A Word of Caution on Shared-State Parallelism
Developing a parallel algorithm is relatively easy as long as threads read and write independent memory chunks. Such an algorithm is referred as embarrassingly parallel. As a rule of thumb, it is best if you can stay within this paradigm. For instance using map-reduce operations, where all threads work on separate memory cells during the map operation, and then a single thread performs a reduction of all temporary results obtained. Sometimes this is not possible, or you want to get to the next level to get better performance. Beware, designing correct and efficient parallel algorithms with threads communicating in a shared memory system is a whole new world. We cannot even scratch the surface here, and this library does not provide much support for it. Nevertheless, it is possible to write such algorithms in CUDA using atomics and synchronization primitives. To use them well, I would advise to take a class (or read a book) on parallel programming and memory consistency models.
Abstract Interpretation Workshop
Hello! During a full week in June, we gather together to study abstract interpretation from its theoretical foundation (lattice theory) to its latest applications (constraint programming, neural network verification).
Abstract interpretation is a formal theory of software verification invented by Radhia and Patrick Cousot in the seventies to detect bugs in programs statically (“at compile-time”) and directly on the source code (not on a model of the program). The main contribution of abstract interpretation is to overapproximate the semantics of a program: violations of properties are always discovered, but we sometimes obtain false-positives. The mathematical framework of abstract interpretation is rich and the papers in the field are complicated for beginners. During this week, we take our time to understand and digest the main ingredients of abstract interpretation.
Further, this framework of approximation turns out to be very general and goes beyond program verification. It was recently applied to constraint reasoning and neural network verification, two topics we also discuss during the week.
PS: Dear PhD students, this workshop does not grant ECTS (but you will still learn something!).
Registration
To have an idea if the rooms are big enough and to avoid running out of coffee, please register here.
Schedule
Week of the 17th June 2024. The coffee (from Jolt coffee shop, mmh, delicious) and pastries will be offered every morning :-) For the brave ones coming to the practice sessions on Monday and Tuesday, coffee and pastries are offered again!
- Monday:
- Tuesday:
- Wednesday (MNO 1.050):
- 9:00-10:30: Introduction to Abstract Interpretation, Pierre Talbot, slides.
- 11:00-13:00: Introduction to Constraint Programming, Manuel Combarro, slides, N-queens.mzn, N-queens-alldifferent.mzn.
- Thursday (MNO 1.040):
- Friday (MNO 1.010):
Speakers





Pierre Talbot (research scientist) ▪ Bruno Teheux (assistant professor) ▪ Thibault Falque (postdoctoral researcher) ▪ Manuel Combarro (PhD candidate) ▪ Yi-Nung Tsao (PhD candidate)
Detailed Program
Find below a detailed description of each session with keywords.
Introduction to Lattice Theory
Partial order ▪ Lattice ▪ Monotone functions ▪ Cartesian product ▪ Complete lattice ▪ Fixpoint ▪ Galois connection
Recommended prerequisite: None.
The goal of these two lectures is to have a first grasp of the mathematical theory underlying abstract interpretation. On the first day, we study partial order and lattices, properties of functions over lattices and several lattice constructions such as products and powerset. On the second day, we overview more advanced concepts such as fixpoint and Galois connection which are particularly useful in abstract interpretation.
Introduction to Abstract Interpretation
Syntax ▪ Reachability semantics ▪ Chaotic iterations ▪ Abstract domains ▪ Widening ▪ Reduced products
Recommended prerequisite: Introduction to Lattice Theory.
The goal is to understand how we can use lattice theory to overapproximate the semantics of program and certify the absence of bugs. We start by reviewing existing verification techniques (e.g., model checking, theorem proving) and discuss the position of abstract interpretation in this landscape.
Introduction to Constraint Programming
Constraint satisfaction problem ▪ Constraint modelling ▪ Propagation ▪ Consistency ▪ Search ▪ Minizinc
Recommended prerequisite: None.
Constraint programming is a powerful paradigm to model problems in terms of constraints over variables. This declarative paradigm solves many practical problems including scheduling, vehicle routing or biology problems, as well as more unusual problems such as in musical composition. Constraint programming describes what the problem is, whereas procedural approaches describe how a problem is solved. The programmer declares the constraints of its problem, and relies on a generic constraint solver to obtain a solution. In this talk, we formally define what is a constraint satisfaction problem (CSP) and the underlying solving procedure. Further, this session will be interactive and time will be allocated so you can try to model and solve your own combinatorial problem in the Minizinc constraint modelling language!
Abstract Constraint Programming
Abstract satisfaction ▪ Solver cooperation ▪ Propagator completion ▪ Table abstract domain
Recommended prerequisites: Introduction to Lattice Theory, Introduction to Abstract Interpretation, Introduction to Constraint Programming.
This talk presents a recent research field!
Combinatorial optimization is a large field of research aiming at finding (best) solutions of logical formulas. There are many research communities working separately on reasoning procedures that work well on different kinds of problems (essentially depending on the underlying domain of discourse and logic predicates). For instances, linear programming solvers are the best to solve linear equations over real numbers but has more difficulty over integers and are unable to deal with non-linearity. SAT solvers can solve very large Boolean formulas but problems can be hard to express compactly when only Boolean variables are available. Constraint programming is a general approach to constraint solving but this generality makes it slower the classes of problem mentioned above. The issue is that each approach is based on different theoretical foundation which makes solver cooperation hard to achieve. We believe abstract interpretation can provide a unified theory of constraint reasoning by abstracting each solving approach in abstract domains, that can then be combined with different products. The first step is to cast the theory of each approach in the framework of abstract interpretation. It has already been started for linear solvers, SAT and constraint programming solvers. In this talk, we focus on the constraint programming approach and present our latest research on this topic.
Octagon Abstract Domain
Octagon ▪ Temporal constraints ▪ Scheduling problems
Recommended prerequisites: Abstract Constraint Programming.
An octagon is an abstract domain able to reason over conjunction of temporal constraints which are restricted linear equation of the form ±x ± y ≤ k where x,y are variables and k a constant.
Octagons offer a particularly interesting compromise between expressiveness and efficiency since they can compute the solutions of a set of temporal constraints in cubic time using the Floyd Warshall shortest path algorithm.
We explain octagon in the context of abstract constraint programming and show how it can enhance solver performance, particularly in scheduling problems.
We also discuss a particular case of reduced product between the propagator completion and octagon abstract domains.
Introduction to Neural Network Verification by Abstract Interpretation
Neural network verification ▪ Robustness metrics ▪ Zonotope abstract domain
Recommended prerequisites: Introduction to Lattice Theory, Introduction to Abstract Interpretation.
This talk presents a recent research field!
Neural networks have become powerful and popular machine learning techniques in recent years. There are many safety-critical applications based on neural networks, such as autonomous driving systems. However, they can be vulnerable to adversarial examples, which are instances with imperceptible perturbations that can lead to incorrect results from neural networks. Therefore, in these safety applications, if any adversarial examples exist, the neural network may make wrong decisions, potentially causing serious consequences. Nowadays, many algorithms and frameworks have been proposed to verify the robustness of neural networks. In this talk, we will introduce how to use abstract interpretation to evaluate the robustness of neural networks. Additionally, we will provide a simple example to demonstrate how to construct a zonotope, which is one of the abstract domains, to verify neural networks.
Parallel Lattice Programming
GPU ▪ Asynchronous iterations ▪ Concurrent constraint programming ▪ Memory consistency ▪ Parallel graph algorithms
Recommended prerequisites: Introduction to Lattice Theory.
This talk presents a recent research field!
We introduce a programming language in which data are lattices, programs are monotone functions, and the execution model is a fixpoint loop. The peculiarity of this language is to have a native parallel operator (P || Q) but no sequence operator (P;Q). Due to its lattice execution model, data races are natively supported (they do not modify the final results), no deadlock can occur, and the implementation is lock-free. We study several algorithms that can be written in this paradigm including a sorting algorithm and the Floyd-Warshall shortest path algorithm. We discuss how this paradigm was applied to write Turbo, a constraint solver based on abstract interpretation that fully executes on the GPU.
References
Here are some references relevant to the various sessions:
Books
- Davey, Brian A., and Hilary A. Priestley. Introduction to Lattices and Order. Cambridge University Press, 2002.
- Cousot, Patrick. Principles of Abstract Interpretation. MIT Press, 2021.
- Apt, Krzysztof. Principles of Constraint Programming. Cambridge University Press, 2003.
- Aws Albarghouthi, Introduction to Neural Network Verification. Foundations and Trends® in Programming Languages (2021).
- Changliu Liu, Tomer Arnon, Christopher Lazarus, Christopher Strong, Clark Barrett and Mykel J. Kochenderfer, Algorithms for Verifying Deep Neural Networks. Foundations and Trends® in Optimization (2021).
Selected Papers
- D’Silva, Vijay, Leopold Haller, and Daniel Kroening. Abstract Satisfaction. POPL 2014.
- Miné, Antoine. The Octagon Abstract Domain. Higher-order and symbolic computation (2006).
Our Papers
- Manuel Combarro Simón, Pierre Talbot, Grégoire Danoy, Jedrzej Musial, Mohammed Alswaitti, and Pascal Bouvry. Constraint Model for the Satellite Image Mosaic Selection Problem. CP 2023.
- Talbot, Pierre, Frédéric Pinel, and Pascal Bouvry. A Variant of Concurrent Constraint Programming on GPU. AAAI 2022.
- Talbot, Pierre, Éric Monfroy, and Charlotte Truchet. Modular Constraint Solver Cooperation via Abstract Interpretation. Theory and Practice of Logic Programming (2020).
- Talbot, Pierre, David Cachera, Eric Monfroy, and Charlotte Truchet. Combining Constraint Languages via Abstract Interpretation. ICTAI 2019.
Sponsors
This project occurs in the context of the project COMOC (ref. C21/IS/16101289), 2021-2025. We thank the Luxembourg National Research Fund (FNR) for this opportunity.
Parallel Programming Competition (2025)
1st Parallel Programming Competition @uni.lu

<section class="grid">
<!-- Left column -->
<div class="nes-container is-dark with-title hero">
<p class="title">Status</p>
<div class="status-line">
<span id="statusBadge" class="nes-badge"><span class="is-warning">STARTS IN</span></span>
<span id="statusLabel">Starts in</span>
<span id="statusCountdown" class="countdown-time" aria-live="polite">--:--:--</span>
</div>
<progress id="statusProgress" class="nes-progress is-primary" value="0" max="100" hidden></progress>
</div>
<!-- Right column -->
<div>
<div class="nes-container is-dark with-title">
<p class="title">Leaderboard</p>
<table class="nes-table is-bordered is-dark leaderboard-table">
<colgroup>
<col style="width:20px"> <!-- Rank -->
<col style="width:70px"> <!-- Team -->
<col style="width:20px"> <!-- Level -->
<col style="width:30px"> <!-- Score -->
<col style="width:40px"> <!-- Last Submission -->
</colgroup>
<thead>
<tr>
<th>Rank</th>
<th>Team</th>
<th>Level</th>
<th>Runtime</th>
<th>Last Submission</th>
</tr>
</thead>
<tbody id="leaderboardBody"></tbody>
</table>
<br />
<p style="font-size: 12px;">!Participants are ranked by level first; if levels are equal, the shorter runtime
prevails.</p>
</div>
</div>
</section>
<div class="nes-container is-dark with-title">
<p class="title">About</p>
<section class="message-list about">
<section class="message -left">
<!-- Balloon -->
<div class="nes-balloon from-left is-dark" data-typer data-typer-speed="30">
<p>The clock is ticking—parallelize as a team or fall behind. Challenge the limits of parallel programming—and take home the prize.</p>
</div>
<i class="nes-kirby"></i>
</section>
<section class="message -right" style="text-align: right;">
<!-- Balloon -->
<div class="nes-balloon from-right is-dark" data-typer data-typer-speed="30" data-typer-delay="5000">
Contest window: 9AM - 8PM
Join us at MNO, room 1.010
</div>
<i class="nes-charmander"></i>
</section>
</section>
</div>
<footer style="display: flex; flex-direction: column; align-items: center; gap: 12px;">
<span class="pill">Organized by Master in High Performance Computing<a
href="https://www.uni.lu/fstm-en/study-programs/master-in-high-performance-computing/"> @MHPC2025</a>, made
with <a href="https://github.com/nostalgic-css/NES.css">NES.css</a> by @Multivac</span>
<!-- <span class="pill">Made with NES.css</span> -->
</footer>
Neuresa Workshop
A full-day of presentations and discussions about the project “Neuro-Symbolic Reasoning for Embedded System Architectures Design” (NEURESA) in cooperation with Cognifyer.
Schedule
Thursday 9 July 2026 in MNO 1.040. The breakfast and coffee are provided by Jolt, as well as the afternoon coffee and pastries.
-
Morning session:
- From 09:00: Breakfast and coffee.
- 09:25-09:30: Pierre Talbot, “Welcome Speech”.
- 09:30-10:00: Hasan Hakan, “Towards Distributed Constraint Solving with CRDT”, CP/SAT doctoral program.
- 10:00-10:30: Manuel Combarro, “Combining an ϵ-Constraint Method with the Pareto Global Constraint”, CP 2026.
- 10:30-11:00: Wei Huang, “Toward Faster Constraint Propagation on GPU”, MHPC Master thesis.
- 11:00-11:30: Anisa Meta, “Equality Abstract Domain Accelerated on GPU”, MHPC Master thesis.
-
Afternoon session:
- 13:00: Coffee and pastries.
- 13:30-14:30: Invited Talk: Mohand Mezmaz, “Language Models as Optimizers: Towards a Framework for Combinatorial Optimization”, slides.
- 14:30-15:00: Patrick Keller, “Presentation of Cognifyer”, slides.
- 15:00-15:30: Clement Poncelet, “A First Prototype Involving Turbo for Solving LLM-Driven Generated Constraints? “, slides.
- 15:30-15:45: break.
- 15:45-16:00: Wenbo Han, “How Many Cycles to Access L1 and Shared Memory on NVIDIA GPUs?”, slides.
- 16:00-16:30: Frédéric Pinel, “Designing a Parallel Fixpoint Algorithm for Breadth-First Search and Future Works”.
- 16:30-17:00: Pierre Talbot, “Towards Turbo 1.3”, slides.
Sponsors
- This project is supported by the Luxembourg National Research Fund (FNR), project AI-HPC BRIDGES 2025/IS/19833538/NEURESA, 2026-2029, PI: Pierre Talbot.
- This project is supported by EuroHPC Development Access Call/EPICURE, project “Parallel Fixpoint-Oriented Programming”, PI: Pierre Talbot.
Turbo
(For a concise introduction to GPU programming, you can check out my tutorial and go through the slides; it is especially useful to know the CUDA vocabulary).
30 August 2023. Turbo is a constraint solver running entirely on the GPU with an architecture based on abstract domains. Intuitively, due to their complex architecture and dynamic data structures, constraint solvers seem to be a poor match for GPUs. Moreover, over the years, new solving techniques have been primarily developed within a sequential mindset, without consideration for parallel execution. The most successful approach to parallel constraint solving is embarrassingly parallel search (EPS) where the problem is decomposed into many subproblems that are solved independently on different cores. Although GPUs have thousands of cores, it is not reasonable to execute one subproblem per core. The primary reason is that a single core does not have its own cache. Cores are actually grouped in streaming multiprocessors (SMs), and all cores in one SM share the same cache (called L1 cache). The L1 cache is only 256KB on the most recent NVIDIA Hopper GPUs (which I don’t have). A quick calculation shows why one subproblem per core is not a viable option. Suppose the domain of a variable is represented by an interval (the lightest you can do, it is more often represented by a set of intervals), hence 8 bytes, a store of 1000 variables takes 8KB of memory. Suppose an SM has 64 (integer) cores, then we need 64*8 = 512KB of cache to fit all the stores at once. We should also store the propagators, and although the stateless propagators can be shared among subproblems, it easily takes up dozens of KB; memory that will not be available for the stores. The threads will end up competing for the caches, and it will generate many memory transfers among the global memory, L2 cache and L1 cache. Memory transfers are usually the most costly operation, hence you try to avoid (or hide) them in a GPU; loading data from the global memory is about 10x slower than from the L1 cache. I am not saying it is impossible to do efficiently, but it seems quite complicated, especially when taking into account warps that are SIMD units of the GPUs (blocks of 32 threads), and thus must all have their data ready in the cache at the same time when executing. This is a hypothesis based on intuition and discussion with GPU experts, but it has not been verified experimentally.
Instead of relying on a “one subproblem per core” design that is so commonly used in parallel constraint solvers, we can execute one subproblem per SM. And parallelism within an SM is achieved by parallelizing propagation! It is worth mentioning that no attempt to parallelize propagation resulted in a faster solver in comparison to simply parallelizing the search. In fact, no modern solver parallelizes propagation. Because most solvers are designed for CPU, it seems that adapting an existing solver to work on GPU is doomed to fail. The design rationale of Turbo is to aim first at a simple but correct parallel design.
I write this technical journal to document my attempts to obtain an efficient GPU-based constraint solver named Turbo. Moreover, because I like my life to be (too) complicated, Turbo is also based on abstract interpretation and implements so-called abstract domains which are mathematical generalizations of the representation of constraints. Let’s embark on this journey!
v1.0.1: Unoptimized Turbo
08 November 2023. We start this adventure with a functional but slow GPU solver. To make it work on the GPU, we had to simplify the architecture of mainstream CPU-based constraint solver in many regards. Let’s start with the current design decisions behind Turbo:
- Pure GPU: From the beginning, we decided to develop Turbo entirely on the GPU, primarily to eliminate memory transfers between the CPU and GPU. We are also forced to design each component with a parallel mindset.
- Propagation: The propagation loop is based on the very first AC1 algorithm: we simply take the first N propagators, run them in parallel, then take the next N propagators, and so on until they are all executed, where N is the number of cores available in the current block. We repeat this operation in a fixed point loop until no change is detected anymore. This implies we do not have a queue of propagators to be woken up or any notion of events in the solver.
- Backtracking: It is based on full recomputation, each time we backtrack, we re-apply all the decisions from the root node; actually, from the root of the current EPS subproblem being solved.
- Embarrassingly parallel search: We dynamically create subproblems that are explored individually by GPU blocks, hence the parallel propagation only happens inside one block.
- Abstract domains: The solver architecture is based on abstract domains which encapsulate solving algorithms dedicated to a particular constraint language, similarly to theories in SMT. However, abstract domains are semantic objects while SMT theories are syntactic objects (and a formal connection exists between the two). Our opinion is that abstract domains are closer to the actual implementation code than SMT theories. Moreover, since a product of abstract domains is also an abstract domain, this framework offers promising perspectives for combining solving algorithms.
- No conflict learning: Conflicts require dynamic data structures to represent the implication graph, and memory allocation is quite costly on GPU, so we currently have no conflict learning.
- Lock-free: Although propagators are sharing the memory, we do not have locks on variables, and actually no lock at all (this is a lie: a single lock used for printing purposes).
- Formally correct: Parallel programming is hard and prone to bugs. The theory behind Turbo relies on lattice theory which enabled us to prove that our lock-free propagation loop is correct.
We have thrown away many optimizations considered essential in mainstream CPU-based constraint solvers. Incidentally, the GPU solver is simpler than a CPU solver, while obtaining similar performances; of course, when comparing to a pure CP solver without SAT learning. Back in 2021, our hypothesis was that drastically simplifying the solver design was necessary to implement a GPU solver and that it could be efficient. We implemented a prototype (Turbo) demonstrating it could work: we obtained similar performances between Turbo and Gecode (on a 6-cores CPU with 12 threads) on RCPSP. More importantly, we laid out the theory behind parallel constraint propagation on GPU and show that, despite the absence of locks, it yielded correct results. These findings were summarized in our AAAI 2022 paper.
For more than one year, I have been refactoring and extending this initial prototype in multiple ways. One goal has been achieved now and Turbo can solve MiniZinc model with two limitations: for now, it only supports integer variables, and all global constraints are decomposed into primitive constraints. The solver Turbo is part of a larger project called Lattice Land, which is a collection of libraries representing lattice data structures. The long-term goal is to be able to reuse these libraries outside of constraint solving, for instance in static analysis by abstract interpretation and in distributed computing using CRDT. The code of Turbo is the glue putting together the required libraries to solve a constraint problem. The new abstract domain design comes with a price: it is less efficient than the prototype. It was expected since the prototype could only handle a very small constraint language with limited architectural overhead. I will try to integrate one by one various optimizations and attempt to first reach the previous efficiency, and then go beyond it.
Benchmarking
To benchmark our progresses, I think it is reasonable to start with a set of easy instances (J30 benchmarks on RCPSP) and a set of harder instances (from MiniZinc competition 2022).
I have selected a subset of the MiniZinc competition benchmarks where I discarded models with set variables (unsupported by Turbo).
For a representative but quicker benchmarking, I selected 1 or 2 instances per problems, arbitrarily varying between small and large instances.
For RCPSP, I randomly selected 19 instances of the J30 dataset.
In the following table, I describe the problems of the benchmarking suite (diffn (1) indicates one occurrence of the global constraint, alldifferent (*) indicates the global constraint occurs in redundant or symmetry breaking constraints).
Description
- Wordpress: Assign software components to hardware units under some constraints.
- ACCAP: Airport check-in counter allocation problem (ACCAP) with fixed opening/closing times.
- Tower: Assign handsets to communication towers to maximize connection quality.
- Team: Make teams of players to maximize happiness and balancing.
- NFC: Network flow global constraint.
- Diameterc-mst: Diameter Constrained Minimum Spanning Tree.
- Stripboard: Layout for electrical components on stripboard: find the most compact layout.
- Blocks world: Find a path of minimum length from an initial configuration to a final configuration of the puzzle.
- Triangular: Puzzle.
- Generalized-peacable Queens: A variant of n-queens with several armies of queens.
- Roster Sickness: Assign employees to work shifts with expertise constraints.
- GFD Schedule: Productions of group of items in various facilities.
- RCPSP: Minimize makespan of tasks under resources constraints.
- Spot 5: Select a subset of photograph to be taken maximizing a weight.
| Problem | #Inst | Kind | Global Constraints | Shape |
|---|---|---|---|---|
| Wordpress | 1 | Allocation | None | Many sum()(). |
| ACCAP | 2 | Allocation | diffn (1) | Precedence constraints. |
| Tower | 1 | Allocation | None | |
| Team Assignment | 1 | Allocation | bin_packing_load, alldifferent (*), bin_packing (1*) | Sums of Boolean. |
| NFC | 1 | Graph | network_flow_cost | Equality/sum constraints. |
| Diameterc-mst | 1 | Graph | None | Many implications / disjunctions. |
| Stripboard | 2 | Packing | diffn (1), disjunctive (1), alldifferent (1*), strictly_decreasing (1*) | Many implications. |
| Blocks world | 1 | Planning | increasing (1), global_cardinality_closed | |
| Triangular | 2 | Puzzle | None | Sum constraints. |
| Generalized-peacable Queens | 1 | Puzzle | regular, global_cardinality (1), all_equal (1), value_precede_chain (1*), lex_lesseq (*) | Almost only global constraints. |
| Roster Sickness | 1 | Scheduling | None | Lexicographic optimization. |
| GFD Schedule | 1 | Scheduling | cumulative, at_most, nvalue | Many implications / disjunctions. |
| RCPSP | 18 | Scheduling | cumulative | Precedence constraints, disjunctions. |
| Spot 5 | 1 | Ad-hoc | table |
Analysis
The primary goal of our initial benchmarking session is to gauge how Turbo measures up against contemporary, state-of-the-art constraint solvers (spoiler: there’s room for improvement). In order to assess the efficiency of Turbo, I compared it against Choco and Or-Tools:
- Turbo v1.0.1: C++/CUDA constraint solver without SAT clause learning and without global constraints.
- Choco v4.10.13: Java constraint solver without SAT clause learning and with global constraints.
- Or-Tools v9.6: C++ constraint solver with SAT clause learning and global constraints.
Since Turbo has no global constraint, I also benchmarked the two previous solvers on problem with decomposition of global constraints, named choco.noglobal and or-tools.noglobal below.
Turbo is developed to run on both CPU and GPU, although it is primarily optimized for GPU use.
We run on the CPU mainly for debugging and comparative efficiency analysis.
The machine on which I performed the benchmarks is a Dell Precision 5820 (desktop computer):
- CPU: Intel Core i9-10900X (3,7GHz, 4,7GHz Turbo, 10C, cache 19,25Mo, HT, 165W).
- RAM: 64 Go, 2 x 32 Go, DDR4 UDIMM.
- GPU: NVIDIA RTX A5000, 24Go, 64 streaming multiprocessors (8192 CUDA cores), 230W.
About the details of the experiments:
- Timeout: 5 minutes per instance (it is relatively small in order to quickly iterate and test new optimizations of Turbo).
- EPS (TurboGPU): generate 1024 subproblems (
-sub 10for “2^10”).
Warning: Before we start, let’s get something straight: the comparison between TurboGPU and other solver is relatively unfair. In particular, because of EPS, TurboGPU uses breadth-first search at the top of the tree, and thus sometimes can get better bounds, while the others use depth-first search and might stay stuck in the left part of the search tree longer. In contrast, on some problems, depth-first search allows TurboCPU to find a better bound because it goes deeper in the search tree. To be completely fair, we should enable parallelism for each solver since most of them support it. We don’t because when you run a race, you don’t try to overtake the 1th runner when you are at the back of the race, you first focus on overtaking the runner in front of you ;-)
Alright, let’s go with the benchmarks, the full Jupyter notebook is available here. We first start by an overview:
The overall results are not surprising. When looking at Choco and Or-Tools, we might wonder if global constraints are worth the investment, especially when clause learning is activated (Or-Tools). In the following, we take a closer look at Choco and Or-Tools:
Here, we only compare the objective bounds and not the time needed to reach the best found objective. Back to Turbo, let’s compare it to our its CPU-version and the baseline solvers:
For future references, it is interesting to have an average of some speed and memory metrics across all problems:
| Metrics | Average | Median |
|---|---|---|
| Nodes per second | 1246.77 | 35.07 |
| Fixpoint iterations per second | 10014.91 | 257.84 |
| Fixpoint iterations per node | 8.48 | 7.11 |
| IDLE SMs at timeout | 13 | |
| Propagators memory | 16.41MB | 13.07MB |
| Variables store memory | 167.78KB | 174.01KB |
| #Problems at optimality | 5 | |
| #Problems satisfiable | 27 | |
| #Problems unknown | 3 |
When comparing the number of nodes per second, we can see that TurboGPU explores around 5 to 10 times more nodes per second than TurboCPU; showing a “purely computational gain” when using the GPU. Just 5x to 10x quicker is actually not that much quicker considering we have 64 streaming multiprocessors, and indicate we are under-using the parallel capacities of the GPU. In the future, I’ll benchmark how efficiently Turbo is using the GPU using the profiling tools of NVIDIA.
You might notice that on RCPSP, TurboCPU is actually better in terms of nodes per second. The reason is that the number of subproblems is not large enough, and some streaming multiprocessors become IDLE because no more problems can be consumed. On two problems, we have only one streaming multiprocessors working, meaning only 1/64 of the GPU is used at the end… We need to improve the EPS algorithm and the decomposition into subproblems.
Finally, let’s look at the fixpoint iterations. On average, Turbo needs to execute each propagator 8 times before reaching a fixpoint, of course it depends on the problem:
To conclude this first benchmarking session, I found the results encouraging, especially when considering how primitive is the propagation loop. I think two important missing optimizations are:
- Preprocessing in the root node, potentially root nodes of each subproblem, to reduce the number of constraints and variables, and avoid useless propagation.
- Disable propagators that are entailed.
See you next time for more benchmarking!
v1.1.{0-1}: Preprocessing
27 December 2023. A simple definition of preprocessing is to prepare the constraint problem hence it can be solved more efficiently by the underlying solver.
The goal of preprocessing is usually to eliminate fixed variables, eliminate satisfied constraints and simplify constraints, for instance by propagating the constants.
In the context of GPU, there is an additional incentive to preprocessing: reducing the memory footprint in order to store the problem in the shared memory (L2 cache).
For now, most of the problems are too large to be entirely stored in shared memory (store of variables and propagators), but the variables can be entirely stored in the shared memory for around 30% of the problems considered.
We have implemented a simple preprocessing class called Simplifier (in lala-core).
After propagating the root node, the preprocessor performs the following simplifications:
- Replace all assigned variables by the constant they are assigned to.
- Create equivalence classes among variables (by detecting
x = yconstraints), select a representative variable in each class, and replace all occurrences of the variables in the equivalence classes by their representative variables. - Remove entailed constraints.
The preprocessing algorithm is in theory suitable for parallel execution on GPU, but it is currently executed on the CPU. The reason is that we want to reduce the problem size to store the variables in the shared memory. But we must decide in which memory to put the variables before we start the GPU kernel; hence we would need to launch the preprocessing in a kernel, to return the data to the CPU and relaunch another kernel with the right shared memory size. There is a solution using CUDA dynamic parallelism, but I did not take the time to explore it yet!
This simple preprocessing step doubles the raw efficiency of the solver as measured by the number of nodes explored per second. Indeed, reducing the problem leads to fewer propagators that need to be executed, which is observed by a reduction of the number of iterations to reach a fixpoint (-14% on average). But the additional speed is also explained by the variables store that has been cut by half on average and the propagators’ memory decreased by 22%. It reduces the pressure on the L1 and L2 caches and more problems can be stored in the shared memory; in our case, one more problem can be stored in shared memory when simplifying.
| Metrics | Average | Δ v1.0.1 | Median | Δ v1.0.1 |
|---|---|---|---|---|
| Nodes per seconds | 2379.95 | +91% | 611.27 | +1742% |
| Fixpoint iterations per second | 12303.02 | +23% | 2273.83 | +882% |
| Fixpoint iterations per node | 7.31 | -14% | 5.9 | -17% |
| #Problems with IDLE SMs at timeout | 9 | 13 | ||
| Propagators memory | 12.65MB | -22% | 7.79MB | -40% |
| Variables store memory | 72.29KB | -57% | 84.1KB | -52% |
| #Problems at optimality | 10 | 5 | ||
| #Problems satisfiable | 22 | 27 | ||
| #Problems unknown | 3 | 3 |
v1.1.0b Increasing the number of subproblems
By default, the number of subproblems created is 1024 (2^10) (option -sub 10).
This choice is rather arbitrary, so I ran additional experiments to see if increasing that number could lead to better results.
The answer is that it is quite hard to choose a good generic number, but overall 4096 (2^12) subproblems gave better results and is the new default for the future versions.
| Metrics | Average | Δ v1.1.0 | Median | Δ v1.1.0 |
|---|---|---|---|---|
| Nodes per seconds | 2529.68 | +6% | 809.31 | +32% |
| Fixpoint iterations per second | 12449.48 | +1% | 3306.37 | +45% |
| Fixpoint iterations per node | 6.77 | -7% | 5.19 | -12% |
| #Problems with IDLE SMs at timeout | 7 | 9 | ||
| Propagators memory | 12.65MB | 0% | 7.79MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.1KB | 0% |
| #Problems at optimality | 11 | 10 | ||
| #Problems satisfiable | 21 | 22 | ||
| #Problems unknown | 3 | 3 |
In particular, we see that increasing the number of subproblems to 4096 contributes to a better average of nodes per second and to solving one more problem to optimality. With more subproblems, the advantage is not as clear, but it is definitely an experiment to try again on future versions of Turbo.
v1.1.1 Partial evaluation
The version 1.1.1 brings partial evaluation of the logical formulas, essentially by aggregating constants and rewriting constraints with fewer operators.
We fully evaluate the expressions without variables, using commutativity laws for addition and multiplication (e.g. in 4 + x + 1 we evaluate 4 + 1).
We apply some standard simplification laws:
- Propagating neutral and absorber elements (using identity and annihilator laws) of conjunction, disjunction, implication, equivalence, addition, subtraction, multiplication and division.
- Eliminating double arithmetic and logical negations.
We also have a bunch of rules to simplify constraints that are generated by the MiniZinc to FlatZinc conversion (let eval be a function evaluating the constant expressions):
- Detecting equalities:
x + (-y) == 0is rewritten tox == y. - Detecting inequalities:
x + (-y) != 0is rewritten tox != y. - Aggregating constants:
x + i != jis rewritten tox != eval(j - i). - Eliminating variable negation:
-x != jis rewritten tox != eval(-j)(and similarly forj != -x).
These rules could be generalized in the future.
This simple optimization leads to another big leap in the number of nodes per second and reduces significantly the memory footprint of propagators. For the first time, there is a problem (nfc_24_4_2) that can be entirely stored in the shared memory (store of variables and propagators). However, the impact of being entirely in the shared memory is not very impressive, with “only” 42% more nodes per second in comparison to v1.1.0b, knowing the average is at 62%. We should validate experimentally if manually managing the shared memory is really worth it, or if the default caching policy of CUDA does a good enough job.
| Metrics | Average | Δ v1.1.0b | Median | Δ v1.1.0b |
|---|---|---|---|---|
| Nodes per second | 4087.42 | +62% | 976.72 | +21% |
| Fixpoint iterations per second | 17837.83 | +43% | 3878.13 | +17% |
| Fixpoint iterations per node | 6.79 | +0.3% | 5.17 | -0.4% |
| #Problems with IDLE SMs at timeout | 8 | 7 | ||
| Propagators memory | 10.34MB | -18% | 7.39MB | -5% |
| Variables store memory | 72.29KB | 0% | 84.1KB | 0% |
| #Problems at optimality | 11 | 10 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 3 |
Overall standing
v1.1.2: (Dis)equality Propagator
07 March 2024. When developing Turbo, I try to keep the number of propagators minimal as it reduces the code and eases the maintenance.
The propagators are represented in an abstract domain called propagators completion (PC) which is essentially an encapsulation of a traditional propagators-based constraint solver inside an abstract domain.
One of the peculiarities is that PC does not contain the store of variables but is parametrized by another abstract domain A that provides access to the variables.
A can be an array of integer intervals or bitsets, as seen in traditional constraint solver, but can be more complicated such as an octagon abstract domain.
This generic design also allows us to parametrize PC by the Cartesian product of any abstract domains, for instance to obtain mixed domains such as interval of integers and interval of floating-point numbers.
It means that we have a single propagator for the constraint x + y <= 10 where x is an integer variable and y a real variable; this is in theory because Turbo does not support floating-point variables yet.
The direct consequence of this abstraction is that we must develop generic propagator functions that do not know exactly the shape of the variables’ domains.
To achieve that, I have a lattice-based propagator of the form t >= u where t is any term (e.g. x + y or S ∪ T), u is a lattice element such as an interval and >= is the associated lattice ordering.
Let project(a, x) be a function of the abstract domain a projecting the domain of the variable x and let’s suppose the type of project(a, x) is the same as the type of u.
For instance, if I write x + y >= [0..5], it means that project(a, x) + project(a, y) should be included in the interval [0..5] according to the interval ordering.
From a logical perspective, it implements the constraints x + y >= 0 and x + y <= 5.
Using some generic lattice operations (essentially projection, ordering and join operator), we can perform the propagation of this constraint.
If the underlying domain is an interval, it will achieve bound consistency, and if it is a bitset, it should achieve arc consistency; I say “should” because I did not formally prove that yet.
This lattice-based propagator is quite compact because it can represent many primitive constraints, for instance:
x == yisx - y >= [0..0].x != yisx - y >= [1.. ∞] \/ x - y >= [-∞..-1].x + y >= 1isx + y >= [1..∞].- …
Therefore, we do not need one propagator per arithmetic comparison operator, but one propagator for all of them. However, this minimalism is problematic for the disequality propagator which is represented by a disjunction. Instead, we have implemented a dedicated propagator for disequality which does not rely on subtraction and disjunction. By duality, this propagator can also be used for propagating equality which avoids a subtraction operation. More fundamentally, for lattices that are pseudo-complemented (usually domains that support holes such as bitset), the disequality propagator is stronger than its disjunctive decomposition.
Interestingly, this propagator does not help to explore more nodes per second, but it finds better objective values for more problems (see the pie diagram below). The number of nodes per second is due to an increase in the number of fixpoint iterations per nodes. As the propagation strength between the two propagators should be the same (at least for intervals), I’m not sure why it takes more iterations to reach the fixpoint. Finally, using these dedicated propagators reduces the propagators’ memory in average, but the median increases. The benchmarking set consists of many instances of the RCPSP problem, for which using these propagators increases the memory. When discarding the RCPSP benchmarks, the median memory footprint of the propagators is actually reduced by a factor of 3, and the average memory is reduced by about 30%! I’m unsure which constraints of the RCPSP model lead to this issue, but due to the limited impact I decided not to investigate.
| Metrics | Average | Δ v1.1.1 | Median | Δ v1.1.1 |
|---|---|---|---|---|
| Nodes per seconds | 3778.83 | -8% | 1049.48 | +7% |
| Fixpoint iterations per second | 16935.39 | -5% | 3847.91 | -1% |
| Fixpoint iterations per node | 7.34 | +8% | 5.16 | 0% |
| #Problems with IDLE SMs at timeout | 8 | 8 | ||
| Propagators memory | 9.01MB | -13% | 8.08MB | +9% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
v1.1.3: Warp Synchronization
07 March 2024. We increase by 15% the number of nodes per second by adding a single line of CUDA code. The trick is to synchronize the warps in the fixpoint loop to reunite threads that have diverged.
In Turbo, the propagators are called “refinement operators” and are essentially monotone function over a lattice structure, we will use both terms interchangeably.
For instance, the octagon abstract domain consists of many small refinement operators implementing the Floyd-Warshall shortest path algorithm.
We compute the fixpoint of the refinement operators over the abstract domain a in a fixpoint loop.
For the curious, the loop in version 1.1.2 is implemented as:
for(size_t i = 1; changed[(i-1)%3] && !is_top[(i-1)%3]; ++i) {
size_t n = a.num_refinements();
for (size_t t = group.thread_rank(); t < n; t += group.num_threads()) {
a.refine(t, changed[i%3]);
}
changed[(i+1)%3].dtell_bot(); // reinitialize changed for the next iteration.
is_top[i%3].tell(a.is_top());
is_top[i%3].tell(local::BInc{*stop});
__syncthreads();
}
Depending on the number of available threads (group.num_threads()), the inner loop iterates the propagators array, refining the first N propagators, then the next N, and so on until all propagators have been executed once.
We keep iterating while at least one refinement operator changes a, and we did not reach an inconsistent state (is_top).
The optimization we introduce in v1.1.3 requires a bit of background explanations on CUDA.
Remember that each streaming multiprocessor (SM) is responsible for solving one subproblem (generated by an EPS-like strategy), thus the fixpoint loop is executed on one SM.
Each SM has 64 physical cores (A5000 GPU), so in theory at most 64 propagators are executed in parallel at the same time.
Similarly to CPU multithreading, it is usually more efficient to have more threads than cores in order to hide data transfer latency.
In Turbo, we obtained the best results by quadrupling the number of cores, to obtain 256 threads per SM.
This group of threads is called a block.
The CUDA scheduler is scheduling groups of 32 threads called warps instead of scheduling individual threads.
A block of 256 threads is thus made of 8 warps, and due to the number of cores, there are only 2 warps at any moment that are executed together.
When talking about GPU, it is common to hear that the GPU “can only execute in parallel the same instructions with different data” (SIMD parallelism).
But this is only true at the level of a warp, for 32 threads.
Two warps can execute completely different instructions without any penalty.
Now, let’s look at what happens if two threads within a warp execute two different instructions.
Suppose if c then P else Q such that the condition is true for 5 threads and false for 27 threads, then the warp is split into two parts and each part is executed sequentially.
For the propagators, it happens quite often that 32 successive propagators are not exactly the same.
For instance, x + y <= k and x - y <= k would cause divergence due to the different arithmetic operators.
Even worst is x * y <= k and x * z <= k that can diverge due to interval multiplication which is not the same depending on the signs of the intervals’ bounds.
In recent versions of CUDA, once threads have diverged, they are not merged back automatically.
It is only when encountering a barrier such as __syncthreads() that they are put back together.
The optimization in version 1.1.3 is to synchronize the threads of each warp (__syncwarp()) after each iteration of the inner loop:
for (size_t t = group.thread_rank(); t < n; t += group.num_threads()) {
a.refine(t, changed[i%3]);
if((t-group.thread_rank()) + group.num_threads() < n) __syncwarp();
}
It leads to better parallelism since at each iteration we start with the full warp of 32 threads and not a warp already split by a previous iteration.
The results show the efficiency of this approach.
Interestingly, it also shows that we need more iterations to reach the fixpoint, which might be due to the fact that the propagators are running in a different order due to __syncwarp().
| Metrics | Average | Δ v1.1.2 | Median | Δ v1.1.2 |
|---|---|---|---|---|
| Nodes per seconds | 4328.83 | +15% | 1240.06 | +18% |
| Fixpoint iterations per second | 21347.57 | +26% | 6519.14 | +69% |
| Fixpoint iterations per node | 8.60 | +17% | 5.31 | +3% |
| #Problems with IDLE SMs at timeout | 9 | 8 | ||
| Propagators memory | 9.01MB | 0% | 8.08MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
There are many possible optimizations to improve the efficiency of the fixpoint loop, in particular to avoid thread divergence. I’m going next to try something very simple: to sort the propagators according to their structures, which should reduce divergence, we’ll see!
The following pie charts show that the version v1.1.3 is strictly better than all others before, which validate the usefulness of our optimizations.
v1.1.{4-5}: Sorting Propagators
28 August 2024. We perform two experiments to reduce thread divergence by sorting propagators, for the reasons mentioned in the previous post. Given a list of propagators representing constraints, we sort on the syntactic shape of the constraint:
- v1.1.4: Sort on the symbol of the outermost predicate of the formula, e.g.
x < yis equal toz + y < x * x, but less thanx <= yfor an arbitrary ordering between < and <=. - v1.1.5: Lexicographic sort on the first predicate symbol followed by the length of the formula, e.g.
length(x < y) = 2 < 3 = length(z + y < x * x).
These are quite simple solutions to reduce divergence while avoiding spending too much time on a sorting algorithm specialized to minimize divergence.
The results are not impressive, and it shows that thread divergence is perhaps not the biggest bottleneck of Turbo.
Nevertheless, given how cheap this optimization is, I decided to keep it.
Note that on some benchmarks where the propagators are very unsorted (e.g. gfd_schedule), sorting increases by 50% the number of nodes explored.
Results v1.1.4
| Metrics | Average | Δ v1.1.3 | Median | Δ v1.1.3 |
|---|---|---|---|---|
| Nodes per seconds | 4439.68 | +3% | 1236.87 | 0% |
| Fixpoint iterations per second | 21659.62 | +1% | 6492.20 | 0% |
| Fixpoint iterations per node | 8.69 | +1% | 5.07 | -5% |
| #Problems with IDLE SMs at timeout | 9 | 9 | ||
| Propagators memory | 9.01MB | 0% | 8.08MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
Results v1.1.5
| Metrics | Average | Δ v1.1.3 | Median | Δ v1.1.3 |
|---|---|---|---|---|
| Nodes per seconds | 4513.37 | +4% | 1243.61 | 0% |
| Fixpoint iterations per second | 21787.61 | +2% | 6612.26 | +1% |
| Fixpoint iterations per node | 8.50 | -1% | 5.38 | +1% |
| #Problems with IDLE SMs at timeout | 9 | 9 | ||
| Propagators memory | 9.01MB | 0% | 8.08MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
v1.1.6: Sharing Propagators
28 August 2024. Each subproblem is currently solved independently in a CUDA block, and the solver state is duplicated on each block.
The propagators are never modified during solving and thus, can safely be shared among the blocks.
Considering the propagators consume on average 9MB (hence 64*9 = 576MB for all blocks) and the L2 cache is only 4MB (on my A5000 card), the data transfers between the global memory and the L2 cache only because of the propagators are quite intense.
In version 1.1.6, I share the propagators among the blocks using a new pointer type called root_ptr (from cuda-battery).
A more classical shared_ptr is not safe to use to share data among blocks because the references counter is not protected against concurrent accesses, which can happen when two blocks call the copy constructor or the destructor of the shared pointer at the same time.
And this can lead to a segmentation fault.
The new root_ptr consider that the first owner of the pointer is the one that will also destroy it, which has the advantage of not required a references counter.
Of course, it is the responsibility of the programmer to delete the pointer after all blocks have terminated.
Once again, and similarly to the version 1.1.5, the improvement is not as great as expected with only 5% more nodes explored on average.
| Metrics | Average | Δ v1.1.5 | Median | Δ v1.1.5 |
|---|---|---|---|---|
| Nodes per seconds | 4758.85 | +5% | 1287.70 | +4% |
| Fixpoint iterations per second | 23376.47 | +7% | 7228.01 | +9% |
| Fixpoint iterations per node | 8.74 | +3% | 5.39 | 0% |
| #Problems with IDLE SMs at timeout | 9 | 9 | ||
| Propagators memory | 9.01MB | 0% | 8.08MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
v1.1.7: Changing the EPS Search Strategy (Bonus)
For fun and profits, I try to change the EPS search strategy to improve the benchmarks in a cheap and easy way. It happens that selecting the smallest value of the smallest domain (first-fail) is a bit better than performing a bisection.
| Metrics | Average | Δ v1.1.6 | Median | Δ v1.1.6 |
|---|---|---|---|---|
| Nodes per seconds | 4527.37 | -5% | 1287.14 | 0% |
| Fixpoint iterations per second | 25015.74 | +7% | 7100.85 | -2% |
| Fixpoint iterations per node | 8.93 | +2% | 5.39 | 0% |
| #Problems with IDLE SMs at timeout | 9 | 9 | ||
| Propagators memory | 9.01MB | 0% | 8.08MB | 0% |
| Variables store memory | 72.29KB | 0% | 84.10KB | 0% |
| #Problems at optimality | 11 | 11 | ||
| #Problems satisfiable | 22 | 22 | ||
| #Problems unknown | 2 | 2 | ||
| #Problem with store in shared memory | 10 | 10 | ||
| #Problem with prop in shared memory | 1 | 1 |
Summary v1.1
The CUDA optimizations performed in the versions 1.1.* did not help to get amazing gain in performance. The best optimization was the preprocessing of the problem (v1.1.1) which has actually nothing to do with GPUs.
After a quick chat with Nvidia engineers that could have a look at a profiling report of Turbo, we identified that the main bottleneck is the high number of registers needed by each block. Turbo is a full application with thousands of lines of code and the call to a single propagator is deep in the functions stack. When the first version of Turbo was developed for the AAAI-2022 paper, it was very simple in terms of capabilities and could only manage scheduling problems. We now manage any kind of discrete constraints, and the solver is based on abstract interpretation, the abstract domain architecture has a cost due to various abstractions. Before we reach the code required for a thread to execute a propagator, we find many local variables on the way that might need to be stored in register. Clearly, the code is not suited at all for a GPU architecture, it could even be surprising it works “that well”.
In the next versions 1.2.*, we are going to focus on splitting the kernel into smaller kernels, perhaps doing the search on the CPU and only the propagation loop on the GPU. Doing it all on the GPU was mainly to reduce data transfers, but clearly, with only 4527 nodes explored per second, the data bandwidth is far from being the bottleneck.
v1.2.0: Refactoring
21 September 2024. Version 1.2 introduces a significant refactoring. Previously, the system operated using a lattice ordering where computations began from bottom and progressed upwards. This resulted in lattices being reversed compared to both abstract interpretation and the conventional ordering in lattice theory, such as with the interval lattice, where bottom typically represents the empty interval. All lattices now follow the standard ordering. Turbo now aligns more closely with the abstract satisfaction framework and terminology as presented by D’Silva et al. in their 2014 paper, Abstract Satisfaction, published at the POPL conference.
Another issue addressed in this update is the incorrect handling of multiplication and division over infinite intervals. While this feature hadn’t been used in prior experiments, resolving it proved non-trivial. It is now sound, although the consistency could be stronger. For instance, I haven’t yet established the rules for dividing by infinity, so the result is currently overapproximated to top. You can find the full changelog here.
Starting with this release, we’ve removed RCPSP instances from the experimental dataset to avoid skewing the metrics. We continue to track the number of nodes processed per second. Thibault, a postdoc on the team, mentioned that this was the first time he had encountered anyone monitoring this particular metric, so I’d like to explain its importance. This metric allows us to compare solvers that are similar in terms of constraint consistency, yet differ in terms of algorithms and optimizations. As noted in earlier posts, some optimizations, such as sharing or sorting propagators, have little to do with constraint programming itself. In these cases, comparing the number of nodes explored per second provides valuable insights. However, it doesn’t make sense to compare nodes-per-second between Choco and OrTools, as their underlying algorithms are different. For now, we’ll continue evaluating this metric across different Turbo versions. To better assess the impact of optimizations, we’re also calculating the normalized average, which, in hindsight, should have been implemented from the start, given that nodes-per-second can vary widely between problems.
Overall, we observed a 7% improvement in exploration speed, with performance dips in only four problems. For the WordPress instance, we noted a small decrease in nodes processed, from 91775 to 86468, which accounts for the lower objective. For ACCAP (a40_f800), the objectives found are very close (2549 vs. 2545), and after rerunning the problem on a laptop, we obtained an objective of 2542, which we’ll attribute to (insignificant) machine fluctuations. The median nodes-per-second metric decreased by 17%, but after closer inspection, the only substantial drop occurred in the triangular/n39.dzn problem, where the nodes-per-second decreased from 828,963 to 686,341. This is because this problem happens to sit at the midpoint of the distribution.
The number of fixpoint iterations per node increased slightly (+4%) on average, likely due to the 16% rise in the number of propagators. The increase in propagators is due to the removal of the “lattice propagator” mentioned in v1.1.2, it did not prove as useful as expected. However, the number of fixpoint iterations is compensated by an 11% increase in the number of iterations per second, so overall efficiency has improved. In conclusion, the refactoring has positively impacted efficiency in terms of nodes-per-second, without significantly affecting the quality of objective bounds.
| Metrics | Normalized average [0,100] | Δ v1.1.7 | #best (_/15) | Average | Δ v1.1.7 | Median | Δ v1.1.7 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 97.45 | +7% | 11 | 10846.81 | +21% | 2287.35 | -17% |
| Fixpoint iterations per second | 98.33 | +11% | 13 | 61386.99 | +23% | 27328.03 | +15% |
| Fixpoint iterations per node | 99.18 | +4% | 4 | 14.67 | +3% | 8.59 | +7% |
| Propagators memory | 99.50 | +16% | 2 | 10.97MB | +16% | 4.30MB | +34% |
| Variables store memory | 99.97 | 0% | 1 | 51.43KB | 0% | 6.74KB | 0% |
| Metrics | Count | Δ v1.1.7 |
|---|---|---|
| #Problems at optimality | 0 | 0 |
| #Problems satisfiable | 13 | 13 |
| #Problems unknown | 2 | 2 |
| #Problem with store in shared memory | 9 | 9 |
| #Problem with prop in shared memory | 1 | 1 |
| #Problems with IDLE SMs at timeout | 2 | 1 |
Shared Memory vs Global Memory
On GPUs, each streaming multiprocessor has an L1 cache, which is extremely fast but relatively small (around 100KB, depending on the GPU model). A portion of the L1 cache, known as shared memory, can be reserved to store frequently accessed data, reducing the need for roundtrips between L1 cache, L2 cache, and global memory.
In our case, there are seven problems where the variable store can be held in shared memory, and one additional problem where both the propagators and the variables store can fit in shared memory. Implementing this optimization is complex, as it requires using C++-templates for all data structures with the memory allocator’s type.
The key question is: does this optimization improve efficiency? To find out, we ran experiments on these seven problems, comparing the performance of Turbo with shared memory optimization against a version of Turbo that uses global memory exclusively (v1.2.0-gmem).
| Metrics | Normalized average [0,100] | Δ v1.2.0-gmem | #best (_/7) | Average | Δ v1.2.0-gmem | Median | Δ v1.2.0-gmem |
|---|---|---|---|---|---|---|---|
| Nodes per second | 100.00 | +5% | 7 | 19068.33 | +4% | 22729.96 | +5% |
| Fixpoint iterations per second | 100.00 | +4% | 7 | 109048.09 | +4% | 58060.52 | +3% |
| Fixpoint iterations per node | 99.76 | 0% | 4 | 6.16 | 0% | 5.38 | 0% |
| Propagators memory | 100.00 | 0% | 0 | 7.07MB | 0% | 0.63MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 4.98KB | 0% | 4.22KB | 0% |
| Metrics | Count | Δ v1.2.0-gmem |
|---|---|---|
| #Problems at optimality | 0 | 0 |
| #Problems satisfiable | 6 | 6 |
| #Problems unknown | 1 | 1 |
| #Problem with store in shared memory | 6 | 0 |
| #Problem with prop in shared memory | 1 | 0 |
| #Problems with IDLE SMs at timeout | 0.0 | 0.0 |
Using shared memory consistently improved the number of nodes processed per second on these problems, and there were no cases where performance was negatively affected. But honestly, +5% was hardly worth the troubles of programming with allocators. That said, it’s possible that the benefits of this optimization are being overshadowed by other GPU-related issues, such as the high number of registers in use. We plan to benchmark it again in the future to determine whether it delivers a more substantial performance boost.
The Impact of Atomics
For correctness, every integer load and store operation must be wrapped in an atomic transaction. Without this, there’s a risk that one thread could write to the first two bytes of an integer while another thread writes to the last two, leading to corrupted data. But what happens if we transgress the rule and remove atomics? To explore this, we address two questions: are the results still correct without atomics, and what is the performance cost of using them?
In terms of raw efficiency, the number of nodes explored per second increased by 13%, which is an interesting gain. Additionally, we didn’t encounter any bugs—all the results were correct. This suggests one of two possibilities: either 32-bit integer loads and stores are inherently atomic on this hardware, or race conditions are so rare that they weren’t detected, even after several hours of computation. Since we can’t be sure, we have to adhere to the formal CUDA semantics, and therefore keep atomics to guarantee correctness!
| Metrics | Normalized average [0,100] | Δ v1.2.0 | #best (_/15) | Average | Δ v1.2.0 | Median | Δ v1.2.0 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 100.00 | +13% | 15 | 12146.40 | +12% | 2680.12 | +17% |
| Fixpoint iterations per second | 99.52 | +13% | 14 | 74963.50 | +22% | 30621.28 | +12% |
| Fixpoint iterations per node | 96.84 | 0% | 7 | 15.24 | +4% | 8.74 | +2% |
| Propagators memory | 100.00 | 0% | 0 | 10.97MB | 0% | 4.30MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 51.43KB | 0% | 6.74KB | 0% |
| Metrics | Count | Δ v1.2.0 |
|---|---|---|
| #Problems at optimality | 0 | 0 |
| #Problems satisfiable | 13 | 13 |
| #Problems unknown | 2 | 2 |
| #Problem with store in shared memory | 9 | 9 |
| #Problem with prop in shared memory | 1 | 1 |
| #Problems with IDLE SMs at timeout | 2 | 2 |
More Benchmarks
We did additional benchmarks to run OrTools and Choco in parallel, Choco with Java11 and Java22, and Turbo on CPU.
| Name | Average nodes-per-second | #Problems at optimality | #Problems SAT | #Problems unknown |
|---|---|---|---|---|
| ortools_9.9_20threads | - | 13 | 2 | 0 |
| ortools_9.9 | 13453.8 | 10 | 4 | 1 |
| ortools.noglobal_9.9 | 15035.4 | 9 | 5 | 1 |
| choco_4.10.15_10threads | 26081.2 | 7 | 7 | 1 |
| choco_4.10.15_java11_10threads | 21082.7 | 7 | 7 | 1 |
| choco_4.10.15_20threads | 9564.2 | 5 | 9 | 1 |
| choco_4.10.15_java11_20threads | 12708.8 | 4 | 10 | 1 |
| choco_4.10.15 | 11527.6 | 2 | 12 | 1 |
| choco_4.10.15_java11 | 10459.6 | 2 | 12 | 1 |
| turbo.gpu_1.2.0_4096_64_256_noatomics | 12146.4 | 0 | 13 | 2 |
| turbo.gpu_1.2.0_4096_64_256 | 10846.8 | 0 | 13 | 2 |
| turbo.gpu_1.1.7_4096_64_256 | 8997.1 | 0 | 13 | 2 |
| turbo.cpu_1.2.0 | 3673.46 | 0 | 13 | 2 |
The version of Java plays a significant role in performance, showing a speedup of 10% to 25% when moving from Java 11 to Java 22, which is now the default version for our experiments. Interestingly, Choco doesn’t handle excessive threading well-one thread per core consistently outperforms two threads per core.
The sequential CPU version of Turbo isn’t performing too badly, exploring 3673 nodes per second. With this in mind, it’s reasonable to target a similar rate per streaming multiprocessor (SM) on the GPU. Given that we have 64 SMs, we should aim to reach at least 235k nodes per second overall.
Improving this metric will be the primary focus for future 1.2.* versions.
Roadmap for 1.2.*
The full GPU design is approaching its limits as the code has grown significantly. After discussions with Nvidia engineers, who are partners in the COMOC project, it appears that the primary inefficiency may be due to the excessive number of registers used. Here’s the plan moving forward:
- Implement a parallel version of the CPU-based Turbo.
- Replace the CPU-based propagation with GPU-based propagation using the parallel version.
- Limit memory transfers, if they become a bottleneck, by transferring only the variables involved in the search strategy.
- Improve the propagators abstract domain to disable entailed propagators.
- Minimize thread divergence by applying a binary decomposition to all constraints.
v1.2.{1,2,3}: Open Hackathon
17 October 2024. We are participating in the Poland Open Hackathon. This page summarizes our progresses and experience. The hackathon spans 2 weeks, beginning with a meeting on 15 October to explain the GH200 architecture that powers the Helios HPC, how to connect and run jobs on it, and then discuss with our mentors: Akif Çördük (Nvidia), Alice Boucher (Nvidia), Michel Herrera Sanchez. Among the mentors, we are fortunate to have two engineers from Nvidia working on cuOpt and a linear programming solver.
During the first meeting, I try to compile Turbo on the Helios HPC and… boom, nvcc is killed by the memory manager due to excessive memory usage.
I encountered a similar problem last year and reported the bug to Nvidia.
The bug was closed as “will not fix”, citing that our kernel is simply too large and needed to be split into smaller kernels.
By adding __noinline__ attributes in key places, I could work around the bug and compile it on sm_70 and sm_86 architectures.
It seems that for sm_90 architectures (of the GH200), the compiler is again doing very aggressive optimizations, and Turbo is just too large for it.
Although the full GPU version avoids memory transfers between the CPU and GPU, we still hit other bottlenecks due to the kernel’s size such as high register pressure. The next meeting is planned on 22 October, for the whole day, and our code is not compiling—not the best start for this hackathon. After a few days, I developed a new hybrid algorithm where the propagation loop runs on the GPU, and the search runs on the CPU. This solution successfully compiles on Helios.
The main event takes place online on 28, 29 and 30 of October and each time we stayed connected online and discussed with the mentors as needed from around 9AM to 3 or 4PM.
Let’s see an executive summary of this hackathon:
- 15 October 2024: Turbo 1.2.0 is not compiling on Helios (ptxas is memkill).
- Reason: Kernel is too large.
- 22 October 2024: New design with a smaller kernel (Turbo v1.2.1).
- The CPU controls the search loop, a kernel is run each time we propagate.
- Use
NCPU threads, each launching a kernel with 1 block using stream. - Compiling, but too slow, too many streams (only
1628nodes per second…).
- 28 October 2024: New design with a persistent kernel (v1.2.2).
NCPU threads communicate withNblocks of a persistent kernel.- Compiling, on-par with the full GPU version.
- 30 October 2024: Deactivation of entailed propagators (v1.2.3).
- Use CUB scan to deactivate propagators that are entailed during search.
- Obtained 10% speed-up.
Hybrid Dive and Solve Algorithm (v1.2.2)
If you don’t know the “propagate-and-search” algorithm of constraint programming, please watch this video I made for the AAAI conference (thanks Covid), starting at 5’30’’ (if you are familiar with GPUs). It also explains how this algorithm is executed in parallel on GPU.
We keep the same algorithm as full-GPU Turbo (option -arch=gpu) but only performs the propagation on the GPU (option -arch=hybrid).
The algorithm consists of two parts:
dive(root, path): From the root of the search tree, commit to the path given to reach a nodesubrootat a fixed depth.solve(subroot): Solve the subproblemsubrootby propagate and search.- When a subproblem has been completely explored, we take a new path to explore if there is any remaining.
During the dive and solve operations, the propagation step is always executed on the GPU. Starting from version 1.2.2, we execute a single kernel and each CPU thread interacts with a single block of that persistent kernel. We compare the full-GPU architecture and this hybrid architecture in the following table (this is on my desktop computer (RTX A5000) due to 1.2.0 not compiling on Helios).
| Metrics | Normalized average [0,100] | Δ v1.2.0 | #best (_/16) | Average | Δ v1.2.0 | Median | Δ v1.2.0 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 93.93 | -4% | 7 | 10271.03 | -1% | 2519.29 | -19% |
| Fixpoint iterations per second | 95.76 | -2% | 7 | 60155.16 | -1% | 31502.75 | -1% |
| Fixpoint iterations per node | 99.76 | +2% | 6 | 16.77 | +15% | 9.00 | 0% |
The hybrid version is slightly less efficient than with the full-GPU version, but considering the number of round-trips between the CPU and GPU I was expecting worst results. Nonetheless, because the kernel is now smaller, we can execute more blocks in parallel. With 128 blocks, we surpass the version v1.2.0 as shown in the following table.
| Metrics | Normalized average [0,100] | Δ v1.2.0 | #best (_/16) | Average | Δ v1.2.0 | Median | Δ v1.2.0 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 94.97 | +5% | 8 | 13475.41 | +29% | 3029.66 | -2% |
| Fixpoint iterations per second | 94.53 | +4% | 8 | 81399.98 | +33% | 33540.01 | +5% |
| Fixpoint iterations per node | 97.39 | 0% | 11 | 15.43 | +5% | 9.20 | +2% |
In terms of the best objectives found, the hybrid version performs better with 64 blocks than with 128 blocks. Indeed, with 128 blocks, we explore a wider search tree at the cost of exploring fewer nodes per block. It is known as the exploration-exploitation dilemma. Until we implement better search strategies and test with a longer timeout, I prefer to stick to the nodes per second metric in order to compare the raw efficiency.
Deactivation of Entailed Propagators and No Atomic (v1.2.3)
A frequent optimization is to avoid calling propagators that are entailed in the fixpoint loop.
To illustrate with a simple example, if x=[1,3], we know for certain that x > 0 is satisfied and will remain satisfy for the rest of the exploration of the current subtree.
Therefore, the propagator implementing x > 0 no longer needs to be executed.
To deactivate entailed propagators, we maintain an array vector<int> indexes giving the indexes of the propagators not yet entailed.
The fixpoint loop can be easily modified to iterate over indexes instead of iterating from 0 to P where P is the number of propagators.
Furthermore, it is easy to verify in parallel that each propagator is entailed, as this is a read-only check.
We can assign each thread to one propagator to check the entailment.
This step produces a mask vector<bool> mask representing which propagators are still active.
The challenging part is to create the new array indexes representing that subset in parallel.
This is a known problem in GPU programming and the scan algorithm (aka. prefix sum) allows to parallelize this step and to copy into a new array indexes2 only the values indexes[i] such that mask[indexes[i]] is true.
This version comes with a more important optimization. It is actually known that tearing on integers is not possible in CUDA (i.e., a thread writing half of an integer while the other thread write the other half). Although it is not formally documented, much code relies on load/store atomicity of primitive types according to our mentors. Therefore, we can safely remove the atomic unlike what I concluded in the v1.2.0 post.
This optimization proves very useful with a 17% increase in nodes per second with 64 blocks, and a 28% increase with 128 blocks. Previously, removing atomic variables accounted for a 13% increase, which is likely a key factor in this speed-up. Deactivating propagators does not hurt, but seems to be less critical than other optimizations.
(-or 64 -arch hybrid)
| Metrics | Normalized average [0,100] | Δ v1.2.2 | #best (_/16) | Average | Δ v1.2.2 | Median | Δ v1.2.2 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.59 | +17% | 14 | 11786.66 | +15% | 3252.29 | +29% |
| Fixpoint iterations per second | 100.00 | +24% | 16 | 81532.87 | +36% | 43905.01 | +39% |
| Fixpoint iterations per node | 99.08 | +5% | 4 | 18.60 | +11% | 9.10 | +1% |
(-or 128 -arch hybrid)
| Metrics | Normalized average [0,100] | Δ v1.2.2 | #best (_/16) | Average | Δ v1.2.2 | Median | Δ v1.2.2 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.96 | +28% | 15 | 18543.27 | +38% | 4082.88 | +35% |
| Fixpoint iterations per second | 100.00 | +35% | 16 | 129459.21 | +59% | 48995.62 | +46% |
| Fixpoint iterations per node | 98.94 | +5% | 4 | 17.00 | +10% | 9.19 | 0% |
This new version also dominates the previous one in terms of objective found. Further, we almost close the gap with the full GPU version v1.2.0 which remains better on only one problem.
Helios Benchmarks
We tested the new versions on Helios which is equipped with a superchip GH200 consisting of a CPU of 72 cores and a H200 GPU with 132 SMs whereas my desktop has a CPU with 10 cores and a RTX A5000 GPU with 64 SMs. The speedup observed with the GH200 demonstrates excellent scalability. Doubling the number of SMs effectively doubles the number of nodes per second. The following table compares the hybrid versions with 1 block per SM on my desktop and Helios.
| Metrics | Normalized average [0,100] | Δ v1.2.2 | #best (_/16) | Average | Δ v1.2.2 | Median | Δ v1.2.2 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 100.00 | +128% | 16 | 33232.29 | +224% | 7796.88 | +209% |
| Fixpoint iterations per second | 100.00 | +137% | 16 | 184996.45 | +208% | 69359.75 | +120% |
| Fixpoint iterations per node | 98.32 | +4% | 6 | 19.11 | +14% | 10.03 | +11% |
We have more than a linear scaling, probably due to the larger L1 cache and other improvement in the H200 GPU. We further improve the nodes per second metric by using 2 blocks per SM (264 blocks).
| Metrics | Normalized average [0,100] | Δ v1.2.2 | #best (_/16) | Average | Δ v1.2.2 | Median | Δ v1.2.2 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.83 | +21% | 14 | 40330.87 | +21% | 9945.53 | +28% |
| Fixpoint iterations per second | 98.86 | +18% | 15 | 258809.97 | +40% | 78749.49 | +14% |
| Fixpoint iterations per node | 97.30 | -2% | 10 | 18.38 | -4% | 9.37 | -7% |
Finally, the version 1.2.3 gives an additional speedup, comparable than the one obtained on my desktop, as shown in the next table.
| Metrics | Normalized average [0,100] | Δ v1.2.2 | #best (_/16) | Average | Δ v1.2.2 | Median | Δ v1.2.2 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.70 | +26% | 14 | 45520.83 | +13% | 15676.14 | +58% |
| Fixpoint iterations per second | 100.00 | +36% | 16 | 360362.70 | +39% | 116916.62 | +48% |
| Fixpoint iterations per node | 98.97 | +7% | 4 | 20.17 | +10% | 10.45 | +12% |
Summary Hackathon
This hackathon was highly productive. It allowed me to verify the correctness of the persistent kernel design (v1.2.2) and to use CUB to eliminate entailed propagators (v1.2.3). More importantly, I discussed the overall design of Turbo, addressing the overly generic approach (code working both on CPU and GPU, using modern C++ patterns, etc.) which hindered performance.
During the three days, we also discussed a new design of propagators and the result will be in a post-hackathon version 1.2.4, so stay tuned!
| short_uid | avg_nodes_per_second | problem_optimal | problem_sat | problem_unknown |
|---|---|---|---|---|
| turbo.hybrid_GH200_1.2.3_4096_264 | 45520.8 | 0 | 14 | 2 |
| turbo.hybrid_GH200_1.2.2_4096_264 | 40330.9 | 0 | 14 | 2 |
| turbo.hybrid_GH200_1.2.3_4096_132 | 36589.3 | 0 | 14 | 2 |
| turbo.hybrid_GH200_1.2.2_4096_132 | 33232.3 | 0 | 14 | 2 |
| turbo.hybrid_RTXA5000_1.2.3_4096_128 | 18543.3 | 0 | 14 | 2 |
| turbo.hybrid_RTXA5000_1.2.2_4096_128 | 13475.4 | 0 | 14 | 2 |
| turbo.hybrid_RTXA5000_1.2.3_4096_64 | 11786.7 | 0 | 14 | 2 |
| turbo.gpu_RTXA5000_1.2.0_4096_64_noatomics | 11684.4 | 0 | 14 | 2 |
| turbo.gpu_RTXA5000_1.2.0_4096_64 | 10412.7 | 0 | 14 | 2 |
| turbo.hybrid_RTXA5000_1.2.2_hybrid_4096_64 | 10271 | 0 | 14 | 2 |
| turbo.hybrid_RTXA5000_1.2.1_hybrid_4096_64 | 1628.89 | 0 | 14 | 2 |
v1.2.4: Ternary Normal Form
27 December 2024. During the hackathon with Nvidia, we profiled the code and discovered that the representation of propagators was problematic.
Let’s take an example with the constraint x * x + y < 5 which is internally represented by the following AST:
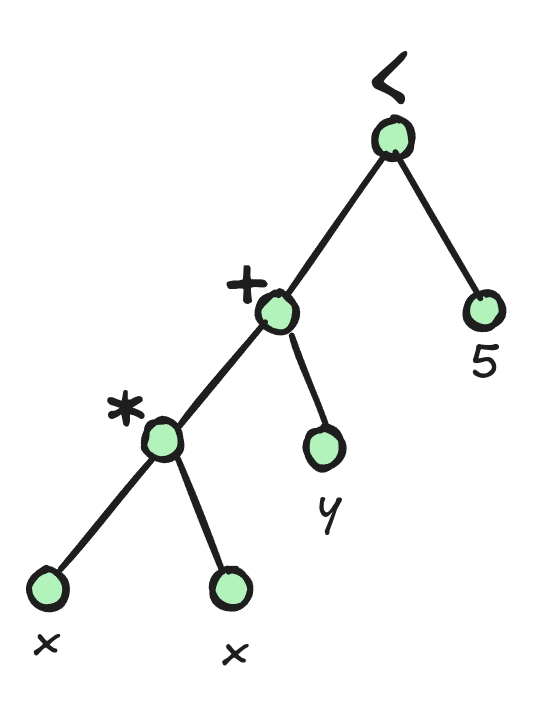
Because the constraints can have any arity and be arbitrarily deep, we have no choice but to represent this tree with pointers and dynamic memory allocation. In Turbo, we used variant and shared_ptr to represent propagators. The propagators are executed using a switch statement of the following form:
switch(term.index()) {
case IVar:
case IConstant:
case INeg:
case IAdd:
case ISub:
case IMul:
// ...
In the profiling report, it is shown that switch(term.index()) generates a lot of uncoalesced accesses.
Previously, we have reduced divergent branches by sorting propagators with the same shape (see sorting propagators).
But the main issue was the uncoalesced accesses to the propagators.
To address this, we propose decomposing the problem into constraints that can be represented without pointers (fixed depth) and that are small (to enable coalesced memory load).
For this purpose, we introduce a new problem decomposition call the ternary normal form (TNF) where all propagators are of the form x = y <op> z with x,y,z variables.
Furthermore, we take a minimal set of operators that includes the arithmetic operators +,-,*,/,min,max and two comparison operators <=, =.
All the other constraints are rewritten into those operators.
The constraint x * x + y < z in TNF is:
t1 = x * x
t2 = t1 * y
ONE = (t2 <= z)
Where t1,t2,ONE are new variables where ONE is initialized to 1.
Note that the symbol = is relational, hence using ONE = (t2 <= z) forces the constraint on the right to be true.
This is called a “reified constraint” in the jargon of constraint programming, but in TNF it has the same representation as any other constraint.
TNF allows us to represent compactly a propagator using:
struct bytecode_type {
Sig op;
AVar x;
AVar y;
AVar z;
};
AVar is an integer representing the index of the variable in the store and Sig is also an integer representing the operator.
Problems in Ternary Normal Form
One obvious drawback of this approach is the increased number of temporary variables and constraints. While the increase in the number of constraints is relatively low and stable across problems (between 1x and 4x), the increase in the number of variables ranges between 1x and 139x in the case of the Wordpress problem. This variability warrants further investigation in the future to explore ways of reducing the number of generated variables.
| Problem | Data | #Vars | #Vars (TNF) | #Constraints | #Constraints (TNF) |
|---|---|---|---|---|---|
| team-assignment | data3_5_31 | 15932.0 | 35445.0 (x2.22) | 25684.0 | 45197.0 (x1.76) |
| generalized-peacable-queens | n8_q3 | 2940.0 | 20186.0 (x6.87) | 8273.0 | 25519.0 (x3.08) |
| spot5 | 404 | 1112.0 | 22053.0 (x19.83) | 8124.0 | 29065.0 (x3.58) |
| nfc | 24_4_2 | 169.0 | 527.0 (x3.12) | 222.0 | 580.0 (x2.61) |
| blocks-world | 16-4-5 | 49447.0 | 109068.0 (x2.21) | 73421.0 | 133042.0 (x1.81) |
| triangular | n39 | 3863.0 | 207966.0 (x53.84) | 105136.0 | 309239.0 (x2.94) |
| accap | accap_a4_f30_t15 | 530.0 | 2319.0 (x4.38) | 993.0 | 2782.0 (x2.80) |
| tower | 100_100_20_100-04 | 12547.0 | 38559.0 (x3.07) | 23257.0 | 49269.0 (x2.12) |
| roster-sickness | small-4 | 4980.0 | 7978.0 (x1.60) | 6067.0 | 9116.0 (x1.50) |
| accap | accap_a40_f800_t180 | 28494.0 | 147451.0 (x5.17) | 58616.0 | 177573.0 (x3.03) |
| diameterc-mst | c_v20_a190_d4 | 3045.0 | 7336.0 (x2.41) | 6962.0 | 11253.0 (x1.62) |
| triangular | n10 | 267.0 | 1370.0 (x5.13) | 765.0 | 1868.0 (x2.44) |
| wordpress | Wordpress7_Offers500 | 667.0 | 92695.0 (x138.97) | 30893.0 | 122921.0 (x3.98) |
| roster-sickness | large-2 | 22952.0 | 29840.0 (x1.30) | 25693.0 | 32653.0 (x1.27) |
| stripboard | common-emitter-simple | 2123.0 | 14581.0 (x6.87) | 4563.0 | 17093.0 (x3.75) |
| gfd-schedule | n55f2d50m30k3_10124 | 32604.0 | 67749.0 (x2.08) | 54575.0 | 89720.0 (x1.64) |
Benchmarks
The following table compares hybrid v1.2.3 and hybrid v1.2.4, both with 128 blocks.
| Metrics | Normalized average [0,100] | Δ v1.2.3 | #best (_/16) | Average | Δ v1.2.3 | Median | Δ v1.2.3 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 83.75 | +29% | 11 | 21808.77 | +18% | 6061.18 | +48% |
| Fixpoint iterations per second | 100.00 | +254% | 16 | 845483.88 | +553% | 143327.93 | +193% |
| Fixpoint iterations per node | 100.00 | +187% | 0 | 40.45 | +138% | 22.76 | +148% |
| Propagators memory | 19.91 | -80% | 15 | 0.85MB | -90% | 0.42MB | -89% |
| Variables store memory | 100.00 | +656% | 0 | 402.75KB | +718% | 208.20KB | +1844% |
Let’s analyze the speedup of this new version v1.2.4. The number of fixpoint iterations per second has increased by 254% which is a very large gain. However, the increase in nodes per second is only 29%, and it increases in only 11 out of 16 problems. There are two reasons behind this discrepancy:
- The convergence of the fixpoint loop is two times slower than in v1.2.3, likely due to improper sorting of the TNF propagators. In all 16 problems, the new version requires more iterations to converge compared to v1.2.3.
- The increase in variables results in fewer problem being stored in shared memory: only 3 out of 16 in comparison to 11 out of 16 before.
The first point is somewhat mitigated by the number of fixpoint iterations per second which almost double, demonstrating the effectiveness of TNF for GPU architecture. Perhaps more surprisingly, the memory footprint of the propagators is much lower than in v1.2.3, with an average reduction of 80%. Although we have more propagators, each one requires only 16 bytes, as opposed to v1.2.3, where propagator representation involved additional overhead from the shared pointer and variant data structures.
As for the full GPU version, we notice a similar behavior (we compare against full GPU v1.2.0 because v1.2.{1-3} were only modifying the hybrid version):
| Metrics | Normalized average [0,100] | Δ v1.2.0 | #best (_/16) | Average | Δ v1.2.0 | Median | Δ v1.2.0 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 89.02 | +28% | 12 | 14467.35 | +24% | 5583.57 | +50% |
| Fixpoint iterations per second | 100.00 | +315% | 16 | 510492.99 | +586% | 136773.93 | +238% |
| Fixpoint iterations per node | 100.00 | +203% | 0 | 40.47 | +167% | 24.07 | +162% |
| Propagators memory | 19.91 | -80% | 15 | 1.03MB | -90% | 0.51MB | -89% |
| Variables store memory | 100.00 | +630% | 0 | 402.93KB | +715% | 208.39KB | +1813% |
Profiling
The hackathon reminded me that we should always prioritize the next improvement based on what the profiler reveals. While this is a well-known principle, it’s easy to forget.
During the hackathon, we mainly used the tool ncu to profile our kernels.
It creates a report that can be visualized with ncu-ui and provides various metrics, such as the overall utilization of the SMs, the number of uncoalesced accesses and their locations in the code, the L1/L2 cache hit rates, warp state statistics, and more.
It was in this report we identified the issues with the previous AST-based representation of the propagators.
Among the remaining issues, the report tells us that warps are spending most of their time waiting on __syncthreads() barriers or global memory loads.
Beyond those low-level GPU optimizations, we can also examine the overall behavior of the constraint solver to identify which parts of the algorithm need further optimization.
To achieve this, we equipped Turbo with time counters to track where most of the time is spent in the code.
Let’s first focus on the full GPU architecture (-arch gpu).
Clearly, the preprocessing time and the time spent eliminating the entailed propagators (from v1.2.3) are negligible. The orange section represents the propagation time, and the green section represents the search time. Prior to optimizing the propagation, the search accounted for about 10-20% of the total time. However, it has now become a clear candidate for further optimization. In the full GPU architecture, the search is handled by a single GPU thread which is why it is quite slow.
Next, we look at the hybrid architecture (-or 128 -arch hybrid).
Firstly, it is clear that searching on the CPU and memory transfers are not (yet) the bottleneck of the hybrid algorithm. The time spent in the fixpoint loop is somewhat similar to the full-GPU architecture. The main difference is the significant amount of time spent waiting for the CPU, as represented by the red section. One possible explanation is that we have too many CPU threads, while the CPU has few cores (only 10). To confirm this hypothesis, we should test this version on the GH200, which is powered by a 72-cores ARM CPU.
Based on these charts, there are at least two opportunities to improve efficiency:
- Continue optimizing the fixpoint loop (this would benefit both architectures, and potentially provide even greater improvements for the hybrid architecture on a CPU with many cores).
- Parallelize the search (this would benefit only the full-GPU architecture).
From a research perspective it is more interesting to focus on the fixpoint loop parallelization. Furthermore, improving the full-GPU version—which does not compile on modern GPUs—is less exciting.
v1.2.5: Trivially Copyable
4 January 2025. If premature optimization is the root of all evil, we show a case where premature generalization is the root of inefficiency on the GPU.
While profiling Turbo, I identified cuda::std::tuple as a performance bottleneck.
The inefficiency stemmed from the Interval class, which was originally implemented using a CartesianProduct abstraction to represent intervals as a pair of lower and upper bounds.
The goal being to stay close to the mathematical definition of interval.
For generality, CartesianProduct supports an arbitrary number of lattice types, storing them internally in a tuple.
However, tuple is not trivially copyable.
This meant that every time an interval was transferred from the CPU to GPU (and vice-versa) the constructor of each element was invoked, incurring a significant overhead.
To address this, I refactored Interval to directly store the lower and upper bounds as members, eliminating the use of CartesianProduct and tuple.
As shown in the table below, this simple refactoring doubled the number of nodes explored per second, for the hybrid version with 128 blocks.
| Metrics | Normalized average [0,100] | Δ v1.2.4 | #best (_/16) | Average | Δ v1.2.4 | Median | Δ v1.2.4 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.98 | +97% | 15 | 34154.16 | +56% | 17018.07 | +180% |
| Fixpoint iterations per second | 99.96 | +104% | 15 | 1102807.71 | +30% | 419951.32 | +192% |
| Fixpoint iterations per node | 99.82 | +4% | 6 | 42.51 | +5% | 25.34 | +11% |
| Propagators memory | 100.00 | 0% | 0 | 0.85MB | 0% | 0.42MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 402.75KB | 0% | 208.20KB | 0% |
Interestingly, the full GPU architecture (-arch gpu) benefits less from this optimization.
| Metrics | Normalized average [0,100] | Δ v1.2.4 | #best (_/16) | Average | Δ v1.2.4 | Median | Δ v1.2.4 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.98 | +8% | 15 | 15135.09 | +5% | 6002.31 | +7% |
| Fixpoint iterations per second | 100.00 | +7% | 15 | 523632.56 | +2% | 151634.36 | +11% |
| Fixpoint iterations per node | 99.43 | -1% | 13 | 40.22 | -1% | 24.03 | 0% |
| Propagators memory | 100.00 | 0% | 0 | 1.03MB | 0% | 0.51MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 402.93KB | 0% | 208.39KB | 0% |
It indicates that non-trivial copy is particularly inefficient when transferring data between CPU and GPU.
Helios (GH200 Superchip)
On Helios (GH200), however, the difference between these two versions becomes negligible. This is likely due to the unified memory architecture of SM90, which reduces the impact of memory transfer costs. The following table shows the difference with 264 blocks and hybrid architecture.
| Metrics | Normalized average [0,100] | Δ v1.2.4 | #best (_/16) | Average | Δ v1.2.4 | Median | Δ v1.2.4 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 98.02 | 0% | 10 | 94111.37 | -3% | 32453.57 | 0% |
| Fixpoint iterations per second | 98.13 | 0% | 8 | 3175947.36 | -7% | 847653.49 | +2% |
| Fixpoint iterations per node | 99.69 | 0% | 10 | 43.71 | 0% | 25.15 | 0% |
| Propagators memory | 99.97 | 0% | 1 | 0.85MB | 0% | 0.42MB | 0% |
| Variables store memory | 99.97 | 0% | 1 | 402.75KB | 0% | 208.20KB | 0% |
It is interesting to compare the H100 to my desktop GPU A5000. Since the A5000 has 64 SMs and H100 has 132 SMs, it should be at least twice as fast on H100. The normalized average shows indeed an increase of +125%, which is a bit more than 2 times faster, but also due to the fact that the GH200 is equipped with a 72-cores CPU, while my desktop has only a 10-cores CPU.
| Metrics | Normalized average [0,100] | Δ A5000 | #best (_/16) | Average | Δ A5000 | Median | Δ A5000 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 100.00 | +125% | 16 | 80590.15 | +312% | 24332.89 | +153% |
| Fixpoint iterations per second | 100.00 | +131% | 16 | 2591379.51 | +335% | 528451.52 | +76% |
| Fixpoint iterations per node | 98.59 | +2% | 7 | 43.04 | +4% | 26.03 | +2% |
v1.2.6: Warp-centric Fixpoint
22 January 2025. Version 1.2.6 introduces a warp-centric fixpoint engine designed to better leverage GPU architecture and improve propagation efficiency.
The previous fixpoint engine followed a straightforward scheduling strategy: with 256 threads and an array of propagators [p1, p2, …, pN], each thread executes propagators spaced 256 apart—thread 1 handles p1, then p257, then p513, and so on. After processing its assigned propagators, each thread hits a barrier and waits for all others to complete before continuing the loop. The process terminates once no propagator changed the domain of any variable.
This strategy corresponds to the AC1 algorithm, first introduced by Mackworth in his 1977 paper Consistency in Networks of Relations. While AC1 is correct, it often performs redundant work—many scheduled propagators have no effect on variable domains, leading to inefficiencies.
Introducing Warp-Centric Propagation
In v1.2.6, we propose a new fixpoint algorithm tailored to GPU architectures: the warp-centric AC1 fixpoint (WAC1). The key insight is that propagators grouped within a warp often share variables. This grouping is not intentional but emerges from how constraint models are written and how constraints are decomposed in ternary form.
WAC1 takes advantage of this spatial locality by allowing each warp to compute a local fixpoint across its 32 propagators before proceeding. Algorithmically, this approach reduces the number of propagator calls. On the hardware side, it reuses bytecode already loaded into cache and registers, improving execution efficiency.
To benchmark this improvement, we use version 1.2.8 and simulate the older versions:
- v1.2.5 ≈ v1.2.8 with
-disable_simplify -arch hybrid -fp ac1 - v1.2.6 ≈ v1.2.8 with
-disable_simplify -arch hybrid -fp wac1
Both configurations use -or 128 -sub 15.
We get a few bug fixes and a new statistics presented below.
Benchmark Results (A5000)
| Metrics | Normalized average [0,100] | Δ v1.2.5 | #best (_/16) | Average | Δ v1.2.5 | Median | Δ v1.2.5 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 98.78 | +19% | 12 | 39881.91 | +5% | 22466.70 | +26% |
| Deductions per node | 68.26 | -31% | 14 | 1117197.24 | -57% | 319343.77 | -32% |
| Fixpoint iterations per second | 65.62 | -34% | 1 | 465136.92 | -49% | 270480.10 | -41% |
| Fixpoint iterations per node | 51.90 | -48% | 16 | 17.07 | -58% | 11.71 | -51% |
| Propagators memory | 100.00 | 0% | 0 | 0.86MB | 0% | 0.42MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 403.25KB | 0% | 208.95KB | 0% |
With AC1, the average number of fixpoint iterations per node is around 40. WAC1 cuts this down to just 17 iterations per node. However, since each WAC1 iteration involves more work—reaching a local fixpoint within a warp—raw iteration counts are not directly comparable. To better evaluate this, we introduce a new metric: deductions per node, representing the number of propagator calls per node. WAC1 reduces deductions by 31%, indicating faster convergence to a fixpoint. This leads to a 19% improvement in normalized nodes explored per second, demonstrating clear performance benefits.
Performance on H100
The H100 GPU shows a similar trend. Note that these benchmarks used the actual v1.2.5 and v1.2.6 versions, so the deductions per node metric was not available. Both experiments ran with -or 264 -sub 12 -arch hybrid.
| Metrics | Normalized average [0,100] | Δ v1.2.5 | #best (_/16) | Average | Δ v1.2.5 | Median | Δ v1.2.5 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 98.54 | +28% | 13 | 96386.82 | +2% | 46832.15 | +44% |
| Fixpoint iterations per second | 62.08 | -38% | 0 | 1438501.41 | -55% | 551572.85 | -35% |
| Fixpoint iterations per node | 47.11 | -53% | 16 | 17.11 | -61% | 12.46 | -50% |
Conclusion
The new warp-centric fixpoint algorithm (WAC1) reduces redundant propagation work and better utilizes GPU hardware capabilities. With up to 31% fewer deductions per node and 19–28% faster node exploration, WAC1 represents a substantial improvement over the traditional AC1 approach. Furthermore, it highlights the importance of fixpoint engines on performance, and we could consider further improving the fixpoint engine in future work.
v1.2.7: Preprocessing Again
21 March 2025. Ternary constraints significantly accelerate parallel propagation—often by an order of magnitude—thanks to their uniform representation. However, this comes with a trade-off: the number of variables and constraints increases significantly, in some cases by up to four orders of magnitude. To address this, I revisited preprocessing, inspired by recent and past work in the constraint programming community, especially:
- I. Araya et al., Exploiting Common Subexpressions in Numerical CSPs, 2008, CP.
- P. Nightingale et al., Automatically improving constraint models in Savile Row, 2017, Artificial Intelligence.
Thanks to the compact structure of ternary representations, implementing preprocessing algorithms becomes simpler and more efficient. The core optimization introduced in this version is the elimination of common subexpressions.
Given two ternary constraints x = y <op> z and a = b <op'> c, if the right-hand sides are syntactically identical (y = b, op = op’, z = c), we can safely eliminate one of the constraints and introduce an equality x = a instead. This small transformation, repeated many times, has a large cumulative impact.
The full preprocessing algorithm will be described in an upcoming paper.
Benchmark Results (A5000)
| Metrics | Normalized average [0,100] | Δ v1.2.6 | #best (_/16) | Average | Δ v1.2.6 | Median | Δ v1.2.6 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 100.00 | +24% | 16 | 46886.52 | +18% | 28322.51 | +26% |
| Deductions per node | 61.01 | -39% | 16 | 812898.02 | -27% | 219665.79 | -31% |
| Fixpoint iterations per second | 90.60 | +4% | 8 | 443548.64 | -5% | 326175.74 | +21% |
| Fixpoint iterations per node | 82.93 | -17% | 16 | 14.99 | -12% | 10.23 | -13% |
| Propagators memory | 65.62 | -34% | 16 | 0.64MB | -25% | 0.25MB | -41% |
| Variables store memory | 61.68 | -38% | 16 | 288.38KB | -28% | 89.04KB | -57% |
Preprocessing in v1.2.7 improves overall solver performance by reducing redundancy at the constraint level. Notably:
- Nodes explored per second increased by 24%.
- Deductions per node dropped by 39%, which means the fixpoint engine converges faster.
- Propagator and variable memory footprints shrank by 34% and 38%, respectively.
- On six benchmarks, the reduced variable store now fits into shared memory (up from three in v1.2.6)
Currently, preprocessing is only applied to the ternarized model. A potential improvement would be to apply subexpression elimination (as in Nightingale et al.) to the original model before ternarization, opening new opportunities for optimization.
v1.2.8: Cost of Abstraction
10 April 2025. Version 1.2.8 introduces a new solving algorithm called barebones, which can be activated via the option -arch barebones.
This architecture strips away some abstractions to reduce kernel code complexity and ensure compatibility with H100 GPUs.
While less generic than the existing algorithms, barebones is significantly more efficient—delivering up to +63% nodes per second and, for the first time, proving optimality on three instances.
Minimalist by Design
The key design decision is to remove dependencies on SearchTree and BAB abstract domains.
The entire search process is implemented in a single file, barebones_dive_and_solve.hpp (about 1000 LOC), compared to 700 LOC for gpu_dive_and_solve.hpp and 800 LOC for hybrid_dive_and_solve.hpp.
Despite losing generality, we retain full functionality. In theory, we could add any constraint to the search tree during solving, but this feature was not used. The only dynamically added constraint is the objective bound—now directly handled with interval domains, reducing overhead.
Similarly, instead of supporting arbitrary branching like x < y ∨ x = y ∨ x > y, we stick to binary strategies such as x < 10 ∨ x ≥ 10, which can be efficiently implemented with two intervals: [xl, 9] and [10, xu].
Parallel Branching & Restoration
With simplified branching and fewer abstractions, search becomes easier to parallelize.
Branching strategies (variable + value selection) now leverage parallel iteration over the variable store, e.g., to find the smallest domain. Restoring the variables’ domain upon backtracking is also done in parallel.
This significantly reduces search time, which is now negligible compared to propagation. This was not the case in the GPU and hybrid versions, as illustrated in previous experiments.
As shown above, on the “roster-sickness_small-4” instance, 191 blocks remain idle at timeout, indicating load imbalance. Improving work decomposition across threads is a near-term priority.
Automatic Block Configuration
Previously, the number of CUDA blocks was set manually using -or, e.g. -or 128.
Now, you can enable automatic configuration via -or 0. It uses CUDA’s cudaOccupancyMaxActiveBlocksPerMultiprocessor to maximize the number of blocks per SM.
We then attempt to fit the variable and propagator stores into shared memory with the selected configuration.
The goal is to favor higher occupancy, even if it means using global memory in some cases.
Benchmark Results (A5000)
Using -or 128 -arch barebones -fp wac1, the performance gains are substantial:
| Metrics | Normalized average [0,100] | Δ v1.2.7 | #best (_/16) | Average | Δ v1.2.7 | Median | Δ v1.2.7 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.87 | +49% | 15 | 211302.32 | +351% | 34413.66 | +22% |
| Deductions per node | 95.80 | -3% | 9 | 815118.16 | 0% | 185548.13 | -16% |
| Fixpoint iterations per second | 99.97 | +47% | 15 | 1541334.10 | +248% | 437091.95 | +34% |
| Fixpoint iterations per node | 96.45 | -2% | 9 | 14.52 | -3% | 9.29 | -9% |
| Propagators memory | 99.99 | 0% | 9 | 0.64MB | 0% | 0.25MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 288.40KB | 0% | 89.06KB | 0% |
With automatic block configuration (-or 0), we gain an additional speed-up:
| Metrics | Normalized average [0,100] | Δ v1.2.7 | #best (_/16) | Average | Δ v1.2.7 | Median | Δ v1.2.7 |
|---|---|---|---|---|---|---|---|
| Nodes per second | 99.17 | +63% | 15 | 262153.55 | +459% | 43555.10 | +54% |
| Deductions per node | 96.52 | -1% | 6 | 823142.05 | +1% | 191625.76 | -13% |
| Fixpoint iterations per second | 99.62 | +65% | 15 | 1925882.39 | +334% | 502630.01 | +54% |
| Fixpoint iterations per node | 97.11 | -1% | 6 | 14.95 | 0% | 9.31 | -9% |
| Propagators memory | 99.99 | 0% | 9 | 0.64MB | 0% | 0.25MB | 0% |
| Variables store memory | 100.00 | 0% | 0 | 288.40KB | 0% | 89.06KB | 0% |
Results Summary
| Metrics | barebones | hybrid |
|---|---|---|
| #Problems at optimality | 3 | 0 |
| #Problems satisfiable | 11 | 14 |
| #Problems unknown | 2 | 2 |
| #Problem with store in shared memory | 1 | 6 |
| #Problem with prop in shared memory | 0 | 0 |
| #Problems with IDLE SMs at timeout | 1 | 2 |
This is the first time the solver could prove optimality on three problems within a 5-minute timeout. It validates the trade-off: by removing abstraction, we unlock performance and simplify the codebase—without losing what matters.
Roadmap 2026
30 March 2026. The year 2025 marks the end of the FNR-funded project COMOC.
Over the course of the project, we developed Turbo, a general-purpose, exact, discrete constraint programming solver that runs entirely on GPU architectures. Turbo supports the discrete subset of MiniZinc and can solve instances from the MiniZinc Challenge benchmark suite. It is already competitive with sequential CP solvers such as Choco, and on some problems it can even outperform OR-Tools.
The algorithms behind the current version of the solver (v1.2.8) were published at AAAI 2026. This paper is the final scientific deliverable of the COMOC project.
The foundations are now in place, and in 2026 we will build a new set of projects on top of them.
This year also marks the start of a new FNR-funded project, NEURESA, in collaboration with Cognifyer. NEURESA stands for Neuro-Symbolic Reasoning for Embedded System Architectures Design. In this project, we investigate how LLMs can support both the modelling stage—specialized here to the design of embedded system architectures—and the solving stage, where they may help improve Turbo’s decisions.
The team is also growing:
- Clément Poncelet joins the NEURESA team as a postdoctoral researcher.
- Yi-Nung Tsao (PhD candidate) is investigating Turbo for continuous problems and neural network verification (NNV).
- Hakan Hasan begins a PhD on distributed constraint solving, and just got his first paper at the PaPoc workshop 2026.
- Anisa Meta joins us to explore GPU-based preprocessing algorithms in the context of her Master’s thesis.
- Wei Huang continues his work on reducing the number of iterations in fixpoint computation, also as part of his Master’s thesis.
- A team of motivated first-year students–Wenbo Han, Eduardo Rodrigez and Ching-Yao Tang–is working on reducing the number of memory transactions during fixpoint computation.
We have an exciting research agenda for 2026. In this post, I discuss some directions we plan to explore.
Continuous Constraint Problems
In recent years, NVIDIA GPUs have tended to include more floating-point cores (FP32) than integer cores (INT32), largely because of their heavy use in machine learning workloads. On Hopper H100 architectures, there are twice as many. For Turbo, this opens two research directions:
- extending Turbo to continuous constraint solving;
- solving discrete constraint problems using floating-point representations (FP32, or even FP4, FP8, FP16, FP64).
The first direction is not trivial, because floating-point arithmetic introduces many subtle difficulties. Fortunately, there is already a rich body of work in this area. The following survey papers and references provide a strong starting point:
- Interval arithmetic: Hickey et al., Interval Arithmetic: from Principles to Implementation, 2003 and Kulisch U., Mathematics and Speed for Interval Arithmetic: A Complement to IEEE 1788
- Inverse interval functions: Goualard F., Interval Extensions of Multivalued Inverse Functions, 2008
- Midpoint of an interval: Goualard F., How do you compute the midpoint of an interval?, 2014
- Computing an over-approximation (branch-and-prune): Granvilliers L., Algorithm 852: RealPaver: an interval solver using constraint satisfaction techniques, 2006 and Chabert et al., Contractor Programming, 2009
- Optimization problems (brand-and-bound): Araya I. et al, Interval Branch-and-Bound algorithms for optimization and constraint satisfaction: a survey and prospects, 2016
- Computing an under-approximation: Araya I. et al., Upper Bounding in Inner Regions for Global Optimization under Inequality Constraints, 2014
The second extension—solving discrete problems with floating-point domains—is not new. It was introduced in CLP(BNR) as a way to unify the representation of Boolean, natural and real-valued domains. An integer domain can be represented by carefully rounding the bounds of a real interval. The same strategy is implemented in IC, the Hybrid Finite Domain / Real Number Interval Constraint Solver of the ECLiPSe constraint logic programming system.
The key intuition is to observe that a 32-bits floating-point number can exactly represent integer in the range [-2^24, 2^24].
There are then two possible ways to propagate constraints over such domains.
As in CLP(BNR) and ECLiPSe, one can apply standard floating-point propagators and then round the result back to an integer domain.
However, this may produce weaker propagation.
For example, [1,1] * [0,1] yields [0,+oo] with a continuous propagator, whereas an integer propagator would infer the tighter domain [0,1].
This suggests an interesting research direction: using integer propagators over floating-point domains. That could lead to a novel contribution. Additional speedups may also be possible by using lower-precision floating-point formats whenever the domains fit safely within the available representation.
Towards Efficient Search Strategy
So far, we have compared Turbo against Choco and OR-Tools using a fixed search strategy–the one specified the MiniZinc model. In practice, however, adaptive search strategy such as wdom/deg, FRBA or pick/dom are often much more effective.
As highlighted in this paper, there are three main ingredients behind the success of modern CP solvers:
- adaptative search strategy;
- solution-based phase saving;
- restarts.
The ACE solver has recently shown strong performances in the XCSP3 competition, including against hybrid SAT+CP solvers based on lazy clause generation.
At the moment, it remains unclear how to parallelize the learning component of SAT solvers effectively on GPUs, so this is not a direction we plan to pursue yet. By contrast, the three components listed above appear much more amenable to efficient GPU implementation.
This extension could become a major milestone for Turbo: it should allow the solver to handle a broader class of problems, and begin competing more seriously in the open category of constraint solving competitions.
Fixpoint Computation Improvement
Turbo’s current fixpoint loop is deliberately simple.
Each warp iterates over all constraints, synchronizes with the others, and, if anything changed, starts another pass.
This mode is exposed as -fp ac1.
A small improvement is available with -fp wac1, where each warp computes a local fixpoint over groups of 32 constraints before synchronizing globally.
We are currently exploring two orthogonal optimization directions:
- converging faster, by reducing the number of fixpoint iterations;
- reducing memory transactions, by improving memory access patterns.
The first direction is primarily algorithmic: it aims to statically schedule constraints in a way that accelerates convergence to the fixpoint.
The second direction is more hardware-oriented: it aims to improve memory coalescing and reduce memory traffic by reordering variables and constraints appropriately.
From preliminary experiments, we expect each of these optimizations to provide a speedup of at least 2x. It is still unclear, however, how strongly they interact, and whether their gains will combine cleanly in practice.
Bounded Existential and Universal Quantifiers
Publications
Foundation
- Theoretical foundation: Pierre Talbot, Frédéric Pinel and Pascal Bouvry. A Variant of Concurrent Constraint Programming on GPU, AAAI 2022
- Practical foundation: Pierre Talbot. A GPU-based Constraint Programming Solver, AAAI 2026
- Ternary constraint network: Pierre Talbot. Decomposition and Preprocessing of Ternary Constraint Networks, arxiv
Extension
- Multi-GPUs: Hakan Hassan, Pierre Talbot. Towards Distributed Constraint Solving with CRDT, PaPoc 2026
About
The lattice land project is developed at the University of Luxembourg by a wonderful team.
Our Sponsors
This is the list of projects supported by Luxembourg National Research Fund (FNR):
- 2026—2029: Neuro-Symbolic Reasoning for Embedded System Architectures Design (NEURESA), FNR AI-HPC BRIDGES 1.1M€ with Cognifyer, ref. 2025/IS/19833538/NEURESA (PI: Pierre Talbot)
- 2026: Parallel Fixpoint-Oriented Programming, EuroHPC Development Access Call/EPICURE, 800h/nodes on Meluxina and 1-month LuxProvide Engineer (PI: Pierre Talbot).
- 2022—2025: A Concurrent Model of Computation for Trustworthy GPU Programming (COMOC), FNR CORE 387k€, ref. C21/IS/16101289 (PI: Pierre Talbot)

